恩培机器视觉
快速搞定 Python 库和环境
Conda + pip 主要好处
使用简单
支持主流操作系统
支持虚拟环境,快速切换多个版本 Python、包
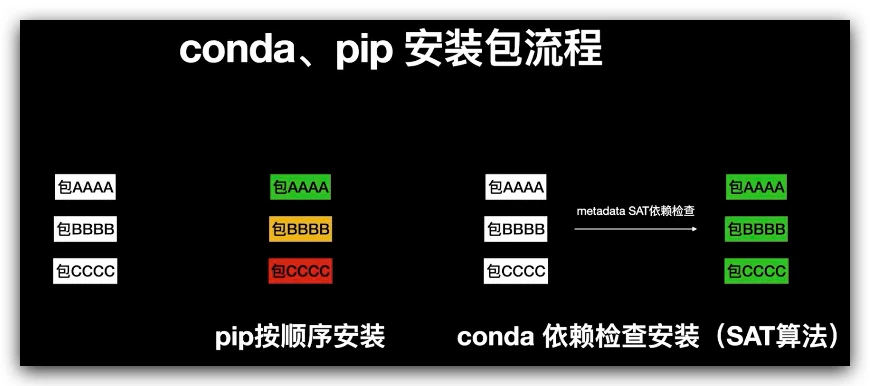
第三方库安装成功率高
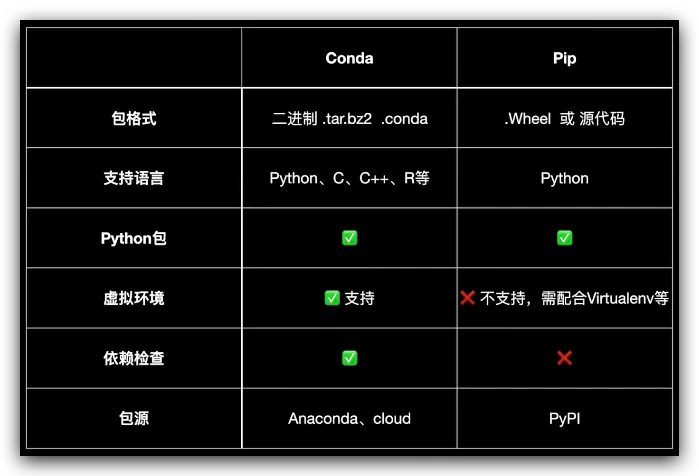
conda 会进行依赖检查,检查不同的包之间的依赖关系,避免包之间的互相影响。
但是 conda 中包的数量远不及 pip 包的数量,所以对于一些冷门的资源,可能还是需要使用 pip。
Python 运行环境:用 Conda 创建虚拟环境
Python 包安装三板斧:Conda>pip>编译安装
1. 下载安装 Conda 软件
https://docs.conda.io/en/latest/miniconda.html

2. 创建 Python 虚拟环境
列出所有环境:conda env list
创建环境:conda creat --name 环境名称英文
进入环境:conda activate 环境名称
退出环境:conda deactivate
删除环境:conda remove --name 环境名称 --all
创建指定 Python 版本环境:conda create --name 环境名称 python=3.7
3. Conda/pip 安装第三方包
国内加速镜像
windows 及其他系统 conda 换源方法:
TUNA 还提供了 Anaconda 仓库与第三方源(conda-forge、msys2、pytorch 等, 查看完整列表 )的镜像,各系统都可以通过修改用户目录下的 .condarc 文件。Windows 用户无法直接创建名为 .condarc 的文件,可先执行 conda config --set show_channel_urls yes 生成该文件之后再修改。
注:由于更新过快难以同步,我们不同步 pytorch-nightly, pytorch-nightly-cpu, ignite-nightly 这三个包。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud即可添加 Anaconda Python 免费仓库。
运行 conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
运行 conda create -n myenv numpy 测试一下吧。
windows 及其他系统 pip 换源方法:
Windows
临时使用:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple
永久使用:
第一步:在 C:\Users\Administrator 目录下创建 pip 文件夹
第二步:在第一步创建的文件夹下(C:\Users\Administrator\pip)创建 pip.ini 文件
第三步:记事本编辑保存 pip.ini 文件内容为以下部分:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple/
[install]
trusted-host = pypi.tuna.tsinghua.edu.cnMacOS 系统
临时使用:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple
永久使用:
执行以下语句
cd ~
mkdir .pip
cd .pip
nano pip.confpip.conf 写入
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple/
[install]
trusted-host = pypi.tuna.tsinghua.edu.cn保存 pip.conf
安装 OpenCV
conda install opencv⚠️注意:此时如果你没有进入conda的环境,那么就是在base里面安装opencv!
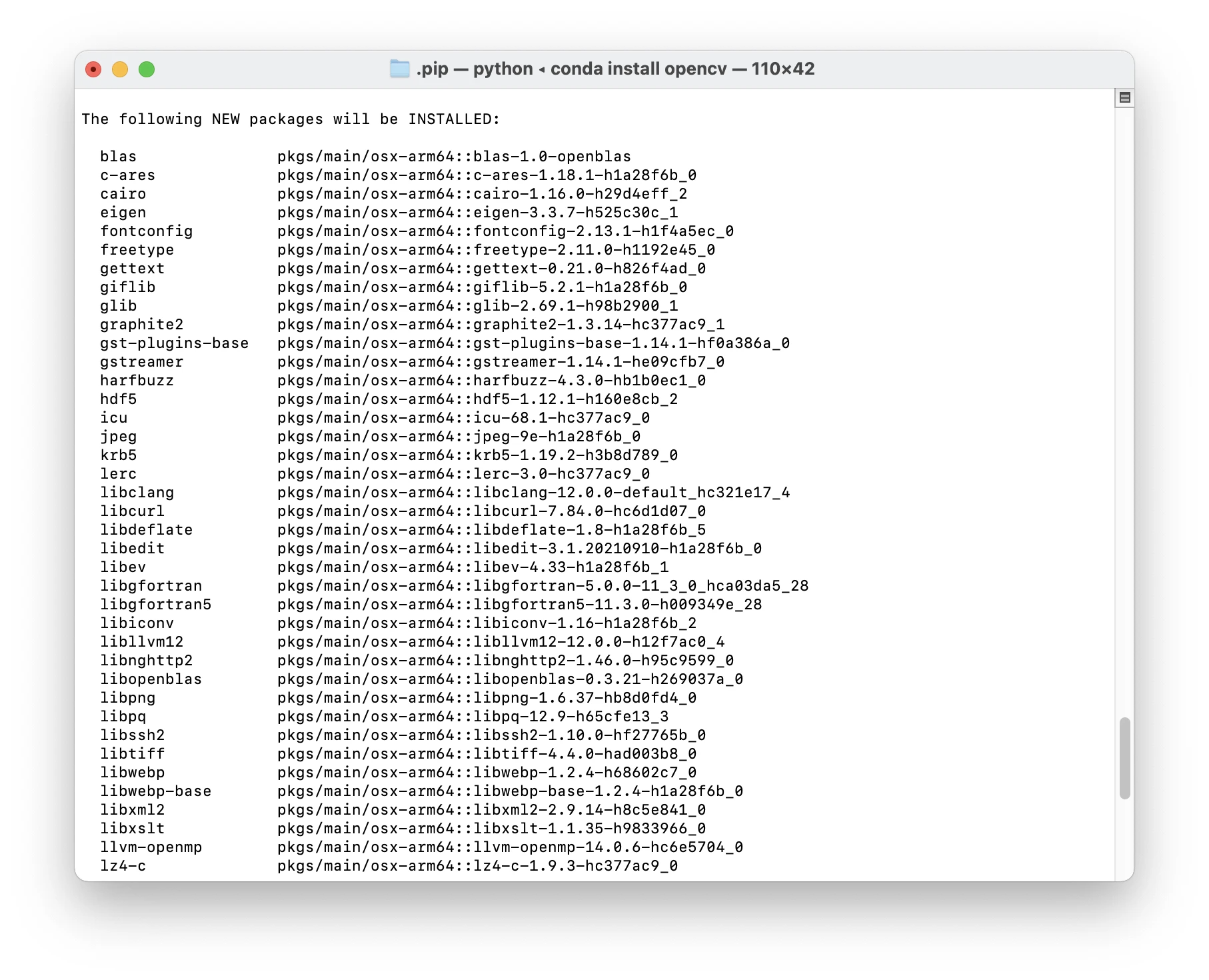
conda install mediapipe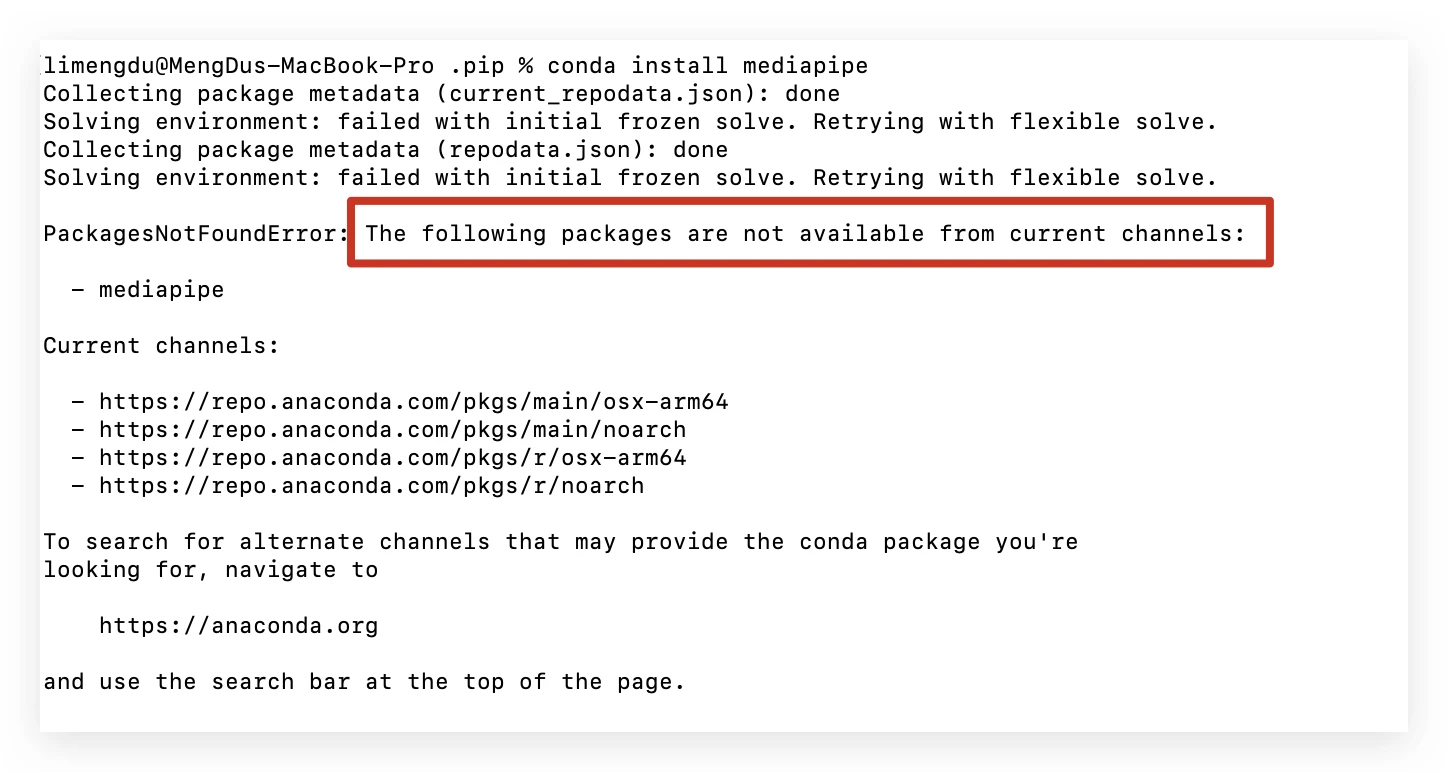
这就属于是比较小众冷门的包,需要使用第二种方式 pip 安装。
python -m pip install mediapipe⚠️注意:此时如果你没有进入conda的环境,那么就是在base里面安装mediapipe!
M1 芯片的苹果电脑,安装 mediapipe:
pip install mediapipe-silicon
要求:
Python: version 3.8 - 3.11
PIP: version 20.3+
4. 运行 Demo 程序
"""
演示 Demo
"""
# 导入 opencv
import cv2
import numpy as np
import math
# 导入 mediapipe:https://google.github.io/mediapipe/solutions/hands
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
model_complexity=0,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
# 读取视频流
cap = cv2.VideoCapture(0)
# 获取画面宽度、高度
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
while True:
ret,frame = cap.read()
# 镜像
frame = cv2.flip(frame,1)
frame.flags.writeable = False
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 识别
results = hands.process(frame)
frame.flags.writeable = True
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# 如果有结果
if results.multi_hand_landmarks:
# 遍历双手
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS,
mp_drawing_styles.get_default_hand_landmarks_style(),
mp_drawing_styles.get_default_hand_connections_style())
# 显示画面
cv2.imshow('demo',frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()终端运行:
conda creat --name lesson1
conda activate lesson1
conda install opencv
pip install mediapipe
cd 文件夹路径
python demo.py效果展示:

思考:
Q:如何知道一个程序应该装哪些包?
A:解决办法一——报错缺什么去搜索引擎搜索需要安装什么包
解决办法二——看程序里面是否有提供说明文件
后续的课程内容请自行在自己的环境内进行。
Numpy 和图像基础
Jupyter Lab
安装:
conda install -c conda-forge jupyterlab
conda install jupterlab (换源后)
或:
pip install jupyterlab
运行:
jupyter-lab
用浏览器打开地址: http://localhost:8888/
小提示:在 jupyter notebook 里面,使用 shift+tab 键可以唤出函数的帮助文档。
Numpy 基础用法
一个列表,可以使用 np.array(list_a) 转化成 np 的列表类型 numpy.ndarry。
np.arrange(0,10)可以快速创建 0~9 的一维数组。
np.arrange(0,10,2)可以快速创建 0~9 的偶数一维数组。
np.ones()可以创建一个全是 1 的数组。
np.zeros()可以创建一个全是 0 的数组。
np.ones(shape=(10,3))可以创建创建一个 10x3 的数组。
np.random.randint(0,100,10)可以创建 10 个 0~99 的随机整数。
arr.reshape((5,2))可以将数组 arr 转成 5x2 的形式。
# 为了了解图像本质,我们需要先了解一下数组和矩阵的概念
# 首先回忆一下,如何创建一个列表
list_a = [1,2,3,4,5]# 打印一下
list_a
>[1,2,3,4,5]# 使用 type 命令查看数据类型,
type(list_a)
>list# 可以看到是 Python 的列表
# 再创建一个列表,使这个列表的元素仍然是列表
list_b = [ [1,2], [3,4], [5,6] ]# 打印列表
list_b
>[ [1,2], [3,4], [5,6] ]# 通过找数字索引,打印第 list_b 第 2 个元素的第 1 个元素
list_b[1][0]
>3# 这种结构我们也叫数组,比如 list_a 是一维数组,list_b 是二维数组
# 为了更高效的处理数组,我们常用 numpy 在这个包
# 首先导入 numpy 包,重命名一下
import numpy as np# 那 numpy 如何创建数组呢?
# 可以用 Python 列表直接转换
# 首先创建一个 Python 列表
list_c = [1,2,3,4]# 检查类型
type(list_c)
>list# 在使用 np.array()将 Python 列表转换为 numpy 的数组
my_array = np.array(list_c)# 我们检查一下 my_array 的类型,
type(my_array)
>numpy.ndarry# 可以看到这个变量已经是 numpy 的数组了
# 打印一下
my_array
>[1,2,3,4]# 那 numpy 还有一些内置函数可以快速地创建数组
# 比如我们使用 np.arange()可以快速创建连续数字的数组
# 比如我创建一个 0~9 的一维数组
np.arange(0,10)
>array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])# jupyterlab 中使用 shift+tab 可以查看函数的帮助文档(查看一下,此刻输入 np.arange(),弹出对应函数帮助文档)
# 可以看到这个 arange()函数有 start、stop 和 step 参数,分别代表了起始值,终止值,以及步长
# 如果我希望创建 0~10 中连续偶数的数组,只需将步长设为 2(此刻输入 np.arange(0,10,2))
np.arange(0,10,2)
>array([0, 2, 4, 6, 8])# 还可以用 np.ones 创建全是 1 的数组,(此时输入 np.ones(),弹出帮助说明)
# 比如我要创建一个大小为 3*3 的全 1 数组
np.ones(shape=(3,3))
>array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])# 再创建一个大小为 10*3 的全 1 数组
# 可以看到 10 是行数,3 是列数
np.ones(shape=(10,3))
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])# 或者使用 np.zeros()全 0 数组
# 比如创建大小为 5*5 的全 0 数组
np.zeros(shape=(5,5))
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])# 我们再演示一下 numpy 的一些其他方法
# 首先使用 np.randint 函数一些随机整数
arr = np.random.randint(0,100,10)# 打印一下
arr
>array([53, 86, 55, 17, 87, 12, 28, 95, 2, 44])# 使用 max 获取最大值
arr.max()
>95# 再使用 argmax() 获取最大值的索引
arr.argmax()
>7# 使用 min 函数获取最小值
arr.min()
>2# 使用 argmin 获取最小值索引
arr.argmin()
>8# 使用 mean()方法获取取平均值
arr.mean()
>47.9# 如果要获取 humpy 数组的大小,使用 numpy.shape,
arr.shape
>(10,)# 也可以使用 reshape 函数转换数组的形状,比如我将 arr 转换成 5*2 的数组
arr.reshape((5,2))
>array([[53, 86],
[55, 17],
[87, 12],
[28, 95],
[ 2, 44]])# 可以看到变成了 5 行 2 列
# 再变形成 2 行 5 列
arr.reshape((2,5))
>array([[53, 86, 55, 17, 87],
[12, 28, 95, 2, 44]])# 如果尝试变形为大小为 2*10 呢?看看效果
arr.reshape((2,10))
>---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-34-abc2abe0ff88> in <module>
1 # 尝试错误变形 2*10
----> 2 arr.reshape((2,10))
ValueError: cannot reshape array of size 10 into shape (2,10)# 可以看到报错了,因为变形后的元素要求是 20 个,而我们原数组只有 10 个元素
# 那二维数组,我们在数学上也称为矩阵,我们再看一下 numpy 对矩阵的操作
# 首先创建一个 10*10 的矩阵
matrix = np.arange(0,100).reshape((10,10))
matrix
>array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69],
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89],
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]])# 查看一下大小
matrix.shape
>(10, 10)# 使用中括号中加索引方式,获取矩阵对应元素,比如我获取第 3 行第 5 列元素
matrix[2,4]
>24# 再获取矩阵第 9 行第 7 列元素
matrix[8,6]
>86# 如果要获取某一行所有元素,我们需要使用 numpy 的切片:
# 比如我要获取第 3 行所有元素,只需将第二个位置变成冒号:
matrix[2,:]
>array([20, 21, 22, 23, 24, 25, 26, 27, 28, 29])# 类似的,比如我要获取第 6 列所有元素,只需将第一个位置变成冒号:
matrix[:,5]
>array([ 5, 15, 25, 35, 45, 55, 65, 75, 85, 95])# 查看 shape
matrix[:,5].shape
>(10,)# 用 reshape 恢复成原来的样子
matrix[:,5].reshape((10,1))
>array([[ 5],
[15],
[25],
[35],
[45],
[55],
[65],
[75],
[85],
[95]])# 我们再说 numpy 获取矩阵一个区域的用法
# 再看一下输出一下原来的 matrix
matrix
>array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69],
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89],
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]])# 比如我要获取第 13 行,第 24 列矩阵,我们可以用数字配合冒号的方式来获取
matrix[0:3,1:4]
>array([[ 1, 2, 3],
[11, 12, 13],
[21, 22, 23]])# 当然我们可以使用等号赋值语句,比如我将这些位置赋值 0
matrix[0:3,1:4] = 0# 查看新的矩阵长啥样
matrix
>array([[ 0, 0, 0, 0, 4, 5, 6, 7, 8, 9],
[10, 0, 0, 0, 14, 15, 16, 17, 18, 19],
[20, 0, 0, 0, 24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69],
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89],
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]])# 好,以上就是 numpy 对数组和矩阵的操作用法
图像的本质
每个图片可以看成数组

灰度图片可以理解成是由暗部(0)和亮部(大于零的数字)组成,越接近 255 表示这个区域越亮。
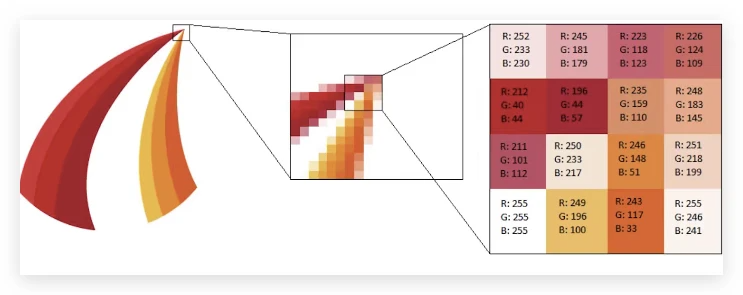


彩色图片就是一个三维数组,使用 Numpy 读取出来的图片就是上述的三维数组。但是计算机并不知道哪一个通道是红色,它只知道有三个表达颜色的通道。所以我们需要标注通道对应的颜色。每一个通道本质是等同于一张灰度图。
# 首先导入 numpy
import numpy as np# 为了在 notebook 中显示图片,导入 matplotlib 库
import matplotlib.pyplot as plt# 加这行在 Notebook 显示图像
%matplotlib inline# 再使用一个 PIL 库,用于读取图像
from PIL import Image# 我在 img 文件夹下放了一张图片(演示一下)
# 我们用 PIL 库读取图片,注意路径要正确
img = Image.open('./img/cat.jpg')# 显示图像
img
# 可以看到这是一张彩色的猫咪图片
# 查看一下变量的类型
type(img)
>PIL.JpegImagePlugin.JpegImageFile# 可以看到这个不是 numpy 的数组格式,那 numpy 还不能处理它
# 首先我们需要将它转化为 numpy 数组,使用 numpy.asarray()函数
img_arr = np.asarray(img)# 查看类型,
type(img_arr)
>numpy.ndarray# 发现已经变成了 numpy 数组,现在我们就可以用 numpy 来处理它了
# 我们查看大小
img_arr.shape# 可以看到这张照片是 1880 像素宽,1253 像素高,3 个颜色通道
# 再使用 matplot 的 imshow()方法显示 Numpy 数组形式的图片
plt.imshow(img_arr)
><matplotlib.image.AxesImage at 0x7f9b86ed0c10>
# 可以看到横坐标和纵坐标显示了图片的长度是 1800 多,高度是 1200 多
# 我们继续对这个图片操作,先使用 numpy 的 copy 方法复制一份原图
img_arr_copy = img_arr.copy()# 显示一下
plt.imshow(img_arr_copy)
# 检查一下大小
img_arr_copy.shape
>(1253, 1880, 3)# 首先使用 numpy 切片,将 R,G,B 三个颜色通道中的 R 红色通道显示出来
plt.imshow(img_arr_copy[:,:,0])
# 大家会发现这个颜色很奇怪,都是翠绿色,为什么会显示成这样呢?
# 我们打开 matplot 的官网关于颜色表 colormap 的说明:
# https://matplotlib.org/stable/gallery/color/colormap_reference.html
# 可以看到默认的颜色:是翠绿色(viridis )。那这个颜色方便色盲观看的
# 我们也可以将 cmap 颜色设置成火山岩浆样式:magma
plt.imshow(img_arr_copy[:,:,0],cmap='magma')
# 我们打印一下红色 R 通道的数组
img_arr_copy[:,:,0]
>array([[111, 111, 111, ..., 193, 195, 197],
[111, 111, 111, ..., 193, 195, 195],
[111, 111, 111, ..., 193, 193, 195],
...,
[213, 213, 213, ..., 215, 214, 214],
[213, 213, 213, ..., 215, 214, 214],
[213, 213, 213, ..., 215, 214, 214]], dtype=uint8)# 好,我们知道,计算机是分不清到底哪一个通道是红色的,每一个颜色通道其实都是一个灰度图,我们首先将 cmap 颜色设置为 gray 灰度
# 看一下
plt.imshow(img_arr_copy[:,:,0],cmap='gray')
><matplotlib.image.AxesImage at 0x7f9b8f8038d0>
# 我们知道,红色通道中的 0 呢就是没有红色,代表纯黑色,而越接近 255 呢,就代表越红,255 就纯红色
# 那看这个灰度图,颜色越浅,表示这里越红
# 我们可以看一下红色通道的灰度图上颜色最浅的就是这个吊坠(鼠标指示)
# 那回到原来彩色图片,可以看到这个吊坠确实是最红的
# 类似的,我们将绿色通道也显示为灰度模式
plt.imshow(img_arr_copy[:,:,1],cmap='gray')
><matplotlib.image.AxesImage at 0x7f9b8f0d9450>
# 那 0 呢代表没有绿色或纯黑色,255 呢就代表纯绿色
# 可以看到,灰度图上颜色越浅,表示这里越绿
# 再看一下蓝色通道
plt.imshow(img_arr_copy[:,:,2],cmap='gray')
><matplotlib.image.AxesImage at 0x7f9b8f75df50>
# 0:没有蓝色或纯黑色,255 代表纯蓝色
# 灰度图颜色越浅,表示这里越蓝 ,可以看到这里相比前面红色、绿色的灰度图,这个花瓶是颜色比较浅的,代表颜色接近蓝色
# 当然,我们可以将某个颜色通道颜色全部设为 0,我们看一下效果,
# 我这里把绿色通道全部变为 0
img_arr_copy[:,:,1] = 0# 显示一下
plt.imshow(img_arr_copy)
><matplotlib.image.AxesImage at 0x7f9b8fc4a550>
# 那会发现画面颜色特别紫,这是因为只剩红色、蓝色通道,而(红+蓝就是紫色)
# 我们再将蓝色通道全部变为 0
img_arr_copy[:,:,2] = 0# 显示一下
plt.imshow(img_arr_copy)
><matplotlib.image.AxesImage at 0x7f9b8bc841d0>
# 那只剩红色通道了,所以画面特别红,
# 那这个红色图片和前面的红色灰度图之所不同,是因为现在是我们三个通道一起合成在看
# 可以查看大小 shape,会发现大小仍然不变
img_arr_copy.shape
>(1253, 1880, 3)# 而单独看一个通道的时候,大小会变化
img_arr_copy[:,:,0].shape
>(1253, 1880)用 OpenCV 玩转图像和视频
为什么学习 OpenCV?
OpenCV 支持对图像缩放、旋转、绘制文字图形等基础操作。
OpenCV 库包含了很多计算机视觉领域常见算法:目标检测、目标跟踪等。
VScode 切换到 Conda 环境实现代码自动补全
切换 Conda 环境,在 VScode 右下角选择即可。
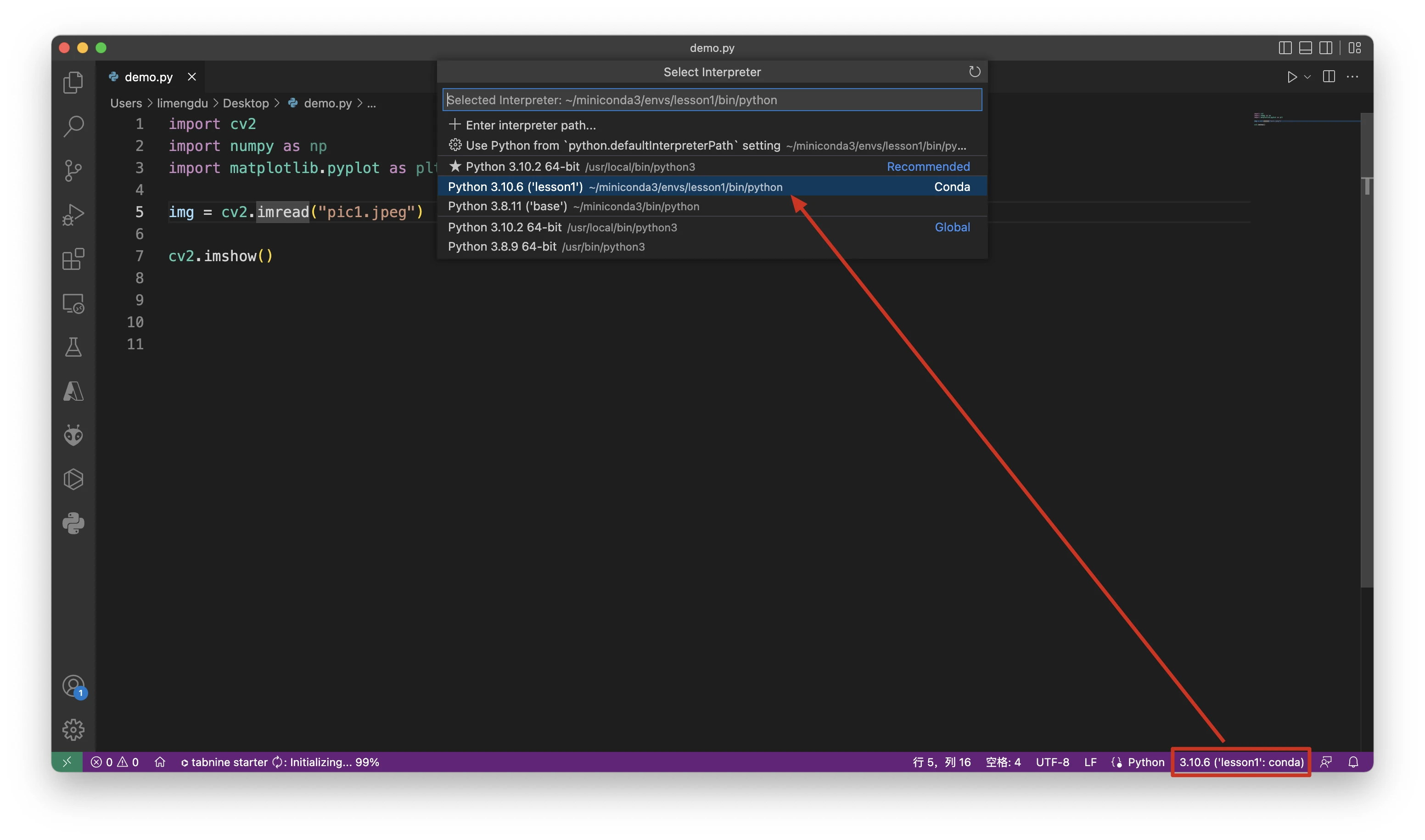
代码自动补全问题,请在 VScode 安装如下插件:
Python (Microsoft) (这个肯定已经装了)
Python Extension Pack (Don Jayamanne)
Pylance (Microsoft) (这个是主角,依赖上面那个扩展)
最开始的时候安装 opencv 时用的是 conda 去安装的。只要我们通过 pip 去安装一次,vscode 中的 pylance 就可以正常使用了。
conda deactivate
pip3 install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple
小提示:推荐使用插件:Tabnine AI Autocomplete for Javascript, Python, Typescript, PHP, Go, Java, Ruby & more,非常强大的代码自动补全 AI 插件。
OpenCV 读取、缩放、翻转、写入图像
# OpenCV 读取、缩放、翻转、写入图像
# 导入必要的包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline# 导入 opencv
import cv2# 使用 opencv 的 imread 方法,打开图片
img = cv2.imread('./img/cat.jpg')# 检查类型,会发现自动转成了 Numpy 数组的形式
type(img)
>numpy.ndarray# 如果打开一张不存在的图片,不会报错,但是会返回空类型
img_wrong = cv2.imread('./img/wrong.jpg')
type(img_wrong)
>NoneTypeimg
>array([[[ 70, 88, 111],
[ 70, 88, 111],
[ 70, 88, 111],
...,
[ 99, 51, 193],
[ 98, 49, 195],
[ 97, 47, 195]],
[[ 70, 88, 111],
[ 70, 88, 111],
[ 70, 88, 111],
...,
[ 99, 51, 193],
[ 98, 49, 195],
[ 97, 47, 195]],
[[ 70, 88, 111],
[ 70, 88, 111],
[ 70, 88, 111],
...,
[ 97, 52, 192],
[ 96, 50, 193],
[ 95, 48, 194]],
...,
[[230, 215, 213],
[230, 215, 213],
[230, 215, 213],
...,
[233, 218, 215],
[234, 217, 214],
[234, 217, 214]],
[[230, 215, 213],
[230, 215, 213],
[230, 215, 213],
...,
[233, 218, 215],
[234, 217, 214],
[234, 217, 214]],
[[230, 215, 213],
[230, 215, 213],
[230, 215, 213],
...,
[233, 218, 215],
[234, 217, 214],
[234, 217, 214]]], dtype=uint8)img.shape
>(1253, 1880, 3)# 为什么会显示的这么奇怪?(OpenCV 和 matplotlib 默认的 RBG 顺序不一样)
plt.imshow(img)
><matplotlib.image.AxesImage at 0x7ff0cd287e10>
# matplotlib: R G B
# opencv: B G R
# 需要调整顺序
# 将 OpenCV BGR 转换成 RGB,cv2.COLOR_可以看到更多转换形式
img_fixed = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)# 显示正常了
plt.imshow(img_fixed)
><matplotlib.image.AxesImage at 0x7ff0cee7e750>
# 另外,我们再读取图片时也可以以灰度模式读取
img_gray = cv2.imread('./img/cat.jpg',cv2.IMREAD_GRAYSCALE)# 只剩 2 个维度,没有了颜色通道
img_gray.shape
>(1253, 1880)# 显示这个灰度图
plt.imshow(img_gray,cmap="gray")
# 我们再显示一下 img_fixed
plt.imshow(img_fixed)
><matplotlib.image.AxesImage at 0x7ff0ccae0e10>
img_fixed.shape
>(1253, 1880, 3)# 使用 resize 缩放(打开函数帮助)
img_resize = cv2.resize(img_fixed,(1000,300))# 显示缩放后的图片
plt.imshow(img_resize)
><matplotlib.image.AxesImage at 0x7ff0cf53b190>
# 可以看到高度被压缩了
img_resize.shape
>(300, 1000, 3)# 翻转图片:0 表示垂直翻转、1 表示水平翻转,-1 表示水平垂直都翻转
img_flip = cv2.flip(img_fixed,-1)
plt.imshow(img_flip)
><matplotlib.image.AxesImage at 0x7ff0cf5926d0>
type(img_flip)
>numpy.ndarray# 先将颜色通道顺序调回 OpenCV 的形式
img_save = cv2.cvtColor(img_flip,cv2.COLOR_RGB2BGR)# 写入 numpy 格式的图片
cv2.imwrite('./img_flip.jpg',img_save)
>TrueOpenCV 在图像上绘制文字、几何图形
# OpenCV 绘制文字和几何图形
# 导入必要的包
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline# 创建一个纯黑色图,纯黑色就是图片的元素全部为 0,这里给一个数据类型为 Int16
black_img = np.zeros(shape=(800,800,3),dtype=np.int16)# 检查 shape
black_img.shape
>(800, 800, 3)# 显示一下
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77dec08f90>
# 首先使用 OpenCV 画一个矩形
# 使用 cv2.rectangle 函数来创建,首先看一下这个函数的帮助文档
# 可以看到分别是:thickness(线粗)
# 那我们在刚才的黑色图片上创建一个矩形
cv2.rectangle(img=black_img,pt1=(100,100),pt2=(400,300),color=(0,255,0),thickness=10)
>array([[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
...,
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]], dtype=int16)# 显示
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77df5ecf10>
# 再画一个正方形在左下角
cv2.rectangle(img=black_img,pt1=(20,550),pt2=(220,750),color=(255,0,0),thickness=10)
>array([[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
...,
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]], dtype=int16)# 显示
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77df92f850>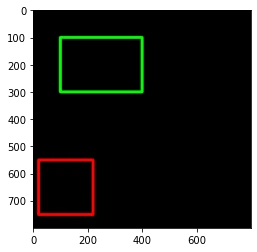
# 在使用 opencv.circle 方法画一个圆
# 看一下帮助文档分别是圆心、半径
cv2.circle(img=black_img,center=(400,400),radius=100,color=(0,0,255),thickness=10)
>array([[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
...,
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]], dtype=int16)# 显示
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77dfc07f50>
# 如果需要实心的,只需将 thickness=-1
# 换一个实心圆
cv2.circle(img=black_img,center=(500,600),radius=50,color=(0,0,255),thickness=-1)
>array([[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
...,
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]], dtype=int16)# 显示
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77dff85c50>
# 再使用 opencv 的 line 函数画一条线,用法和矩形一样
# 我们沿着画面对角线画一条紫色线条
cv2.line(img=black_img,pt1=(0,0),pt2=(800,800),color=(255,0,255),thickness=10)
>array([[[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
[[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
[[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
...,
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 0, 255],
[255, 0, 255],
[255, 0, 255]],
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 0, 255],
[255, 0, 255],
[255, 0, 255]],
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 0, 255],
[255, 0, 255],
[255, 0, 255]]], dtype=int16)# 显示
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77e02bb590>
# 我们再使用 OpenCV 添加文字
# 首先是英文
# 定义字体
font = cv2.FONT_HERSHEY_PLAIN# 然后使用 puttext 方法
cv2.putText(img=black_img,text="Python",org=(500,150),fontFace=font,fontScale=4,color=(255,0,255),thickness=5,lineType=cv2.LINE_AA)
>array([[[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
[[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
[[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
...,
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 0, 255],
[255, 0, 255],
[255, 0, 255]],
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 0, 255],
[255, 0, 255],
[255, 0, 255]],
[[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 0, 255],
[255, 0, 255],
[255, 0, 255]]], dtype=int16)# 显示图像
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77e059b450>
# 我们再用画一个多边形
# 重新创建一个黑色图
black_img = np.zeros(shape=(800,800,3))
plt.imshow(black_img)
><matplotlib.image.AxesImage at 0x7f77e08c1e50>
# 画一个多边形
# 定义多边形顶点,这些顶点得以二维数据形式存储
points = np.array( [[400,100],[200,300],[400,700],[600,300] ] ,dtype=np.int32)
points
>array([[400, 100],
[200, 300],
[400, 700],
[600, 300]], dtype=int32)points.shape
>(4, 2)# 然后呢,opencv 比较麻烦,还需转换成三维数组格式
pts = points.reshape((-1,1,2))
pts.shape
>(4, 1, 2)pts
>array([[[400, 100]],
[[200, 300]],
[[400, 700]],
[[600, 300]]], dtype=int32)# 然后使用 OpenCV 的 polyline 方法创建,注意这里还需要用列表形式把点传过去
cv2.polylines(img=black_img,pts=[pts],isClosed=True,color=(255,0,255),thickness=10)
>array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
...,
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
...,
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
...,
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
...,
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
...,
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
...,
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
...,
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])# 显示
plt.imshow(black_img)
>Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
[28]:
<matplotlib.image.AxesImage at 0x7f77dfca52d0>
# 在真实图片上加载文字、图形
# 读取图片
img_cat = cv2.imread('./img/cat.jpg')
img_cat.shape
>(1253, 1880, 3)# 显示图片
# 先转换一下 RBG 顺序
img_cat_fixed = cv2.cvtColor(img_cat,cv2.COLOR_BGR2RGB)
plt.imshow(img_cat_fixed)
><matplotlib.image.AxesImage at 0x7f77df54e910>
# 在图片上添加矩形和圆形
cv2.rectangle(img_cat,(250,200),(750,600),(255,0,255),10)
cv2.circle(img_cat,(1000,450),100,(0,255,0),10)
>array([[[ 70, 88, 111],
[ 70, 88, 111],
[ 70, 88, 111],
...,
[ 99, 51, 193],
[ 98, 49, 195],
[ 97, 47, 195]],
[[ 70, 88, 111],
[ 70, 88, 111],
[ 70, 88, 111],
...,
[ 99, 51, 193],
[ 98, 49, 195],
[ 97, 47, 195]],
[[ 70, 88, 111],
[ 70, 88, 111],
[ 70, 88, 111],
...,
[ 97, 52, 192],
[ 96, 50, 193],
[ 95, 48, 194]],
...,
[[230, 215, 213],
[230, 215, 213],
[230, 215, 213],
...,
[233, 218, 215],
[234, 217, 214],
[234, 217, 214]],
[[230, 215, 213],
[230, 215, 213],
[230, 215, 213],
...,
[233, 218, 215],
[234, 217, 214],
[234, 217, 214]],
[[230, 215, 213],
[230, 215, 213],
[230, 215, 213],
...,
[233, 218, 215],
[234, 217, 214],
[234, 217, 214]]], dtype=uint8)img_cat_fixed = cv2.cvtColor(img_cat,cv2.COLOR_BGR2RGB)
plt.imshow(img_cat_fixed)
><matplotlib.image.AxesImage at 0x7f77c670af10>
# 再说一下添加中文字体,这个比较麻烦,这里我已经写好了一个函数大家可以直接调用
# 要注意两点:
# 1、对应的字体要安装好或者放在目录下
# 2、不像 cv2.puttext 可以直接生效,因为这里用了各种转换,所以需要用一个变量来保存结果
# 中文比较麻烦
# 导入 PIL 对应包
from PIL import Image, ImageDraw, ImageFont
# 定义一个函数
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
print(type(img))
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype(
"./font/simsun.ttc", textSize, encoding="utf-8")
# 绘制文本
draw.text(position, text, textColor, font=fontStyle)
# 转换回 OpenCV 格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)img_cat = cv2AddChineseText(img_cat, '柠檬', (400,800), textColor=(0, 255, 0), textSize=200)
><class 'PIL.Image.Image'>img_cat_fixed = cv2.cvtColor(img_cat,cv2.COLOR_BGR2RGB)
plt.imshow(img_cat_fixed)
><matplotlib.image.AxesImage at 0x1666e0a60>
课后作业:编写程序,并在 conda 环境下运行。
要求 1:选择一张自己的图片,使用 OpenCV 绘制一个矩形和写一段中文;
要求 2:将图片以真实的色彩展示出来,展示 10 毫秒并且可以通过按下 ESC 键关闭窗口;
要求 3:将处理后的图片保存到源目录,保存的图片也必须是真实色彩。
答案:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 导入 PIL 对应包
from PIL import Image, ImageDraw, ImageFont
#写中文函数
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
print(type(img))
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype(
"./simsun.ttc", textSize, encoding="utf-8")
# 绘制文本
draw.text(position, text, textColor, font=fontStyle)
# 转换回 OpenCV 格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
# 读取
img = cv2.imread("./pic1.jpeg")
#将cv2的BGR格式转换成RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#调整图像大小:宽高
img_fix = cv2.resize(img, (800,600))
#绘制矩形
img_fix = cv2.rectangle(img = img_fix, pt1 = (350,80), pt2 = (630,480), color = (0,255,0))
#写中文
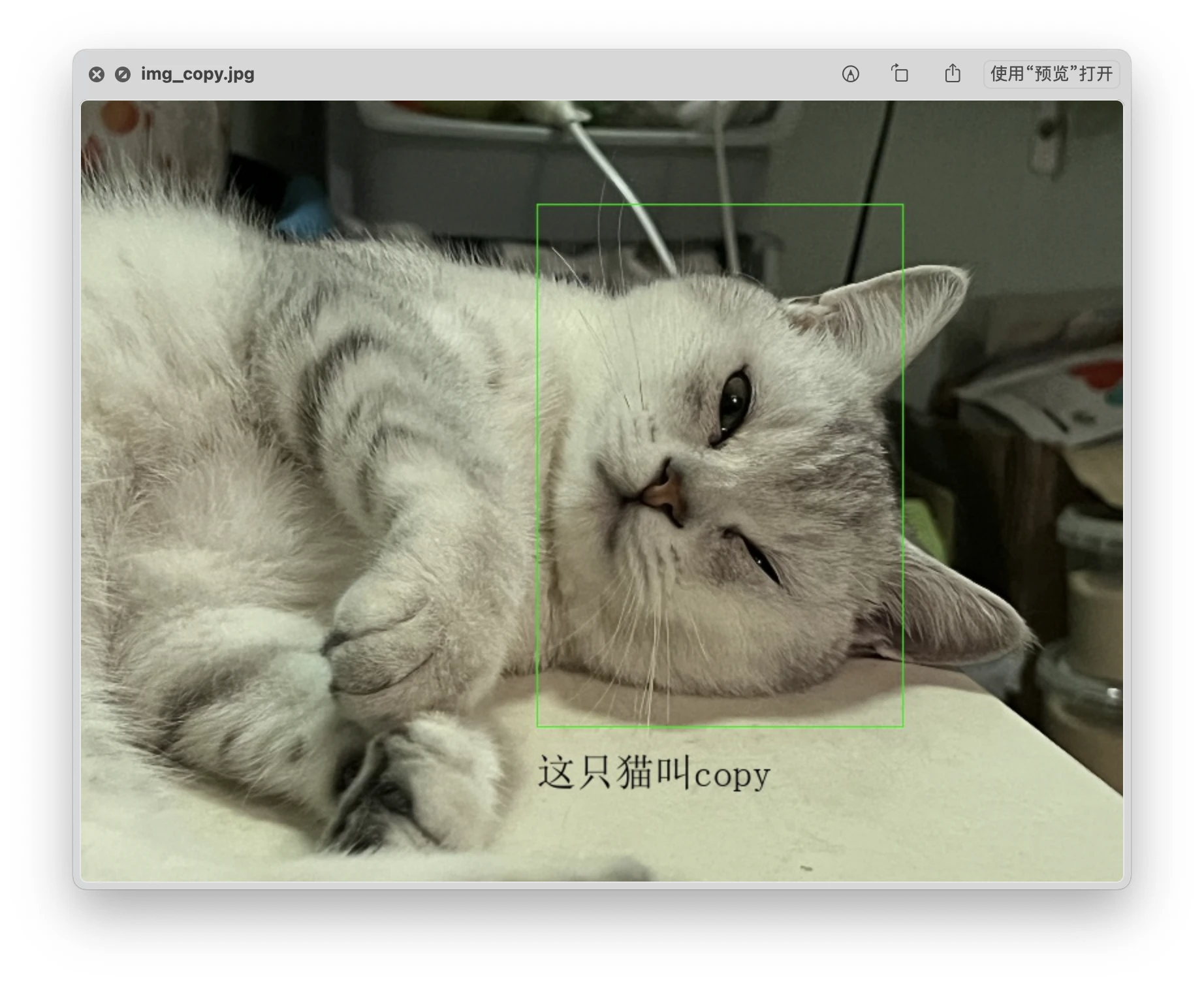
img_fix = cv2AddChineseText(img_fix, "这只猫叫 copy", (350, 500), textColor = (0, 0, 0), textSize = 30)
#恢复颜色
img_fix = cv2.cvtColor(img_fix, cv2.COLOR_RGB2BGR)
while True:
# 不停的显示
cv2.imshow('picture one', img_fix)
# 如果等待至少 10ms,而且按了 ESC 键,也可以用 ord('q')
if cv2.waitKey(10) & 0xFF == 27:
break
cv2.imwrite('./img_copy.jpg', img_fix)
# 关闭所有窗口
cv2.destroyAllWindows()效果展示:
OpenCV 视频操作
OpenCV 连接 webcam 或 USB 摄像头
- OpenCV 读取摄像头并显示:导入必要库→调用摄像头→读取一帧帧图像→镜像→(灰度显示)→显示画面→退出条件(Q键退出)→释放窗口
import cv2
import numpy as np
# 使用 VideoCapture,读取默认摄像头,后面的数字表示摄像头的编号,如果有多个摄像头可以换成其他数字
video = cv2.VideoCapture(0)
# 再使用 cap.read()读取视频流,类似照片,他会以一帧帧的图片返回,所以我们需要用一个循环语句来一直获取
while True:
# 返回的是元组
ret, frame = video.read()
#镜像
frame = cv2.flip(frame, 1)
#灰度
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 显示图像
cv2.imshow("Mac camera", frame)
# 退出条件: q
if cv2.waitKey(10) & 0xFF == ord("q"):
break
video.release()
cv2.destroyAllWindows()OpenCV 操作视频文件
关于视频流保存函数 VideoWriter 方法的使用 🔗 : https://docs.opencv.org/4.x/dd/d43/tutorial_py_video_display.html
- OpenCV 保存视频流:导入必要库→调用摄像头→配置保存信息(位置,名称,格式,帧率,画面宽高)→读取一帧帧图像→镜像→保存画面→(灰度显示)→显示画面→退出条件(Q键退出)→释放窗口、释放写
import cv2
import numpy as np
# 使用 VideoCapture,读取默认摄像头,后面的数字表示摄像头的编号,如果有多个摄像头可以换成其他数字
video = cv2.VideoCapture(0)
#帧率、宽高
fps = 20
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
#配置视频保存信息
'''
这里使用 OpenCV 的 VideoWriter 方法来,我们看一下官网他是如何使用的
可以看到第一个参数是文件名,然后是 fourcc 编码,然后是 FPS 帧率,再是画面大小
这里需要注意的是 Fourcc 编码,我们再看一下文档,可以看到
Windows 系统建议用 DIVX 编码
macOS 系统建议永 MJPG、DIVX、X264
推荐用 X264、DIVX,一般 macOS 和 Windows 都适用
写法需要注意*'X264'
FPS 帧率一般根据摄像头的帧率来填写,比如我的是 20
高度、宽度可以自定义,不过我们也可以直接和原画面一样,使用 cap.get 方法获取
'''
writer = cv2.VideoWriter('./capture.mp4',cv2.VideoWriter_fourcc(*'MJPG'),fps,(width,height))
# 再使用 cap.read()读取视频流,类似照片,他会以一帧帧的图片返回,所以我们需要用一个循环语句来一直获取
while True:
# 返回的是元组
ret, frame = video.read()
#镜像
frame = cv2.flip(frame, 1)
#灰度
#frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#保存视频
writer.write(frame)
# 显示图像
cv2.imshow("Mac camera", frame)
# 退出条件: q
if cv2.waitKey(10) & 0xFF == ord("q"):
break
#释放句柄
writer.release()
video.release()
cv2.destroyAllWindows()- OpenCV 读取视频文件:导入必要库→调用视频路径→异常提醒→读取一帧帧图像(可以通过sleep方法延缓视频播放速度)→播放视频→播放完视频后关闭窗口 & 退出条件(Q键退出)→释放窗口
from logging import exception
import cv2
import numpy as np
import time
# 使用 VideoCapture,读取默认摄像头,后面的数字表示摄像头的编号,如果有多个摄像头可以换成其他数字
video = cv2.VideoCapture("./capture.mp4")
try:
while True:
# 返回的是元组
ret, frame = video.read()
#延缓视频播放速度
time.sleep(0.05)
#镜像
frame = cv2.flip(frame, 1)
#灰度
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 显示图像
cv2.imshow("Local camera", frame)
# # 退出条件: q
if cv2.waitKey(10) & 0xFF == ord("q"):
break
except:
print('No such file!')
#释放句柄
video.release()
cv2.destroyAllWindows()OpenCV 在视频上添加文字、图形
- OpenCV 在摄像头视频流上添加文字和图形:导入必要库→调用摄像头→读取一帧帧图像→将cv2默认的BGR格式转换成RGB格式→对图像进行操作(作画)→镜像→(灰度显示)→恢复图片色彩(将RGB转换回BGR)→显示画面→退出条件(Q键退出)→释放窗口
可以考虑显示帧率在左上角,帧率计算方式:导入时间库,在程序开始设置一个起始时间,在每个画面处理函数中再获得一个时间,两个时间相减得到每个画面的处理时间。用 1 除以每个画面的处理时间即为帧率。
from logging import exception
import cv2
import numpy as np
import time
# 使用 VideoCapture,读取默认摄像头,后面的数字表示摄像头的编号,如果有多个摄像头可以换成其他数字
video = cv2.VideoCapture(0)
#系统启动时间
start_time = time.time()
try:
while True:
# 返回的是元组
ret, frame = video.read()
#将cv2的BGR格式转换成RGB
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
#镜像
frame = cv2.flip(frame, 1)
#灰度
#frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#计算帧率
current_time = time.time()
fps = int(1/(current_time - start_time))
start_time = current_time
#设置显示帧率
font = cv2.FONT_HERSHEY_PLAIN
frame = cv2.putText(img = frame, text = str(fps), org = (20, 50), fontFace = font, fontScale = 3, color = (0, 255, 0), thickness = 3, lineType = cv2.LINE_AA)
#恢复颜色
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# 显示图像
cv2.imshow("Local camera", frame)
# # 退出条件: q
if cv2.waitKey(10) & 0xFF == ord("q"):
break
except:
print('No such file!')
#释放句柄
video.release()
cv2.destroyAllWindows()实战项目 1:AI 手势虚拟拖拽方块
步骤:
OpenCV 获取视频流
在画面上画一个方块
通过 mediapipe 获取手指关键点坐标( https://google.github.io/mediapipe/solutions/hands )
判断手指是否在方块上
根据食指和中指指尖的坐标,利用勾股定理计算距离,当距离较小且都落在矩形内,则触发拖拽(矩形变色);
矩形跟着手指动;
两指放开,则矩形停止移动
完善:画面显示 FPS 等信息
标准答案:
# 导入OpenCV
import cv2
# 导入mediapipe
import mediapipe as mp
# 导入其他依赖包
import time
import math
# 方块管理类
class SquareManager:
def __init__(self, rect_width):
# 方框长度
self.rect_width = rect_width
# 方块list
self.square_count = 0
self.rect_left_x_list = []
self.rect_left_y_list = []
self.alpha_list = []
# 中指与矩形左上角点的距离
self.L1 = 0
self.L2 = 0
# 激活移动模式
self.drag_active = False
# 激活的方块ID
self.active_index = -1
# 创建一个方块,但是没有显示
def create(self, rect_left_x, rect_left_y, alpha=0.4):
self.rect_left_x_list.append(rect_left_x)
self.rect_left_y_list.append(rect_left_y)
self.alpha_list.append(alpha)
self.square_count += 1
# 更新位置
def display(self, class_obj):
for i in range(0, self.square_count):
x = self.rect_left_x_list[i]
y = self.rect_left_y_list[i]
alpha = self.alpha_list[i]
overlay = class_obj.image.copy()
if (i == self.active_index):
cv2.rectangle(overlay, (x, y), (x + self.rect_width, y + self.rect_width), (255, 0, 255), -1)
else:
cv2.rectangle(overlay, (x, y), (x + self.rect_width, y + self.rect_width), (255, 0, 0), -1)
# Following line overlays transparent rectangle over the self.image
class_obj.image = cv2.addWeighted(overlay, alpha, class_obj.image, 1 - alpha, 0)
# 判断落在哪个方块上,返回方块的ID
def checkOverlay(self, check_x, check_y):
for i in range(0, self.square_count):
x = self.rect_left_x_list[i]
y = self.rect_left_y_list[i]
if (x < check_x < (x + self.rect_width)) and (y < check_y < (y + self.rect_width)):
# 保存被激活的方块ID
self.active_index = i
return i
return -1
# 计算与指尖的距离
def setLen(self, check_x, check_y):
# 计算距离
self.L1 = check_x - self.rect_left_x_list[self.active_index]
self.L2 = check_y - self.rect_left_y_list[self.active_index]
# 更新方块
def updateSquare(self, new_x, new_y):
# print(self.rect_left_x_list[self.active_index])
self.rect_left_x_list[self.active_index] = new_x - self.L1
self.rect_left_y_list[self.active_index] = new_y - self.L2
# 识别控制类
class HandControlVolume:
def __init__(self):
# 初始化medialpipe
self.mp_drawing = mp.solutions.drawing_utils
self.mp_drawing_styles = mp.solutions.drawing_styles
self.mp_hands = mp.solutions.hands
# 中指与矩形左上角点的距离
self.L1 = 0
self.L2 = 0
# image实例,以便另一个类调用
self.image = None
# 主函数
def recognize(self):
# 计算刷新率
fpsTime = time.time()
# OpenCV读取视频流
cap = cv2.VideoCapture(0)
# 视频分辨率
resize_w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
resize_h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 画面显示初始化参数
rect_percent_text = 0
# 初始化方块管理器
squareManager = SquareManager(150)
# 创建多个方块
for i in range(0, 5):
squareManager.create(200 * i + 20, 200, 0.6)
with self.mp_hands.Hands(min_detection_confidence=0.7,
min_tracking_confidence=0.5,
max_num_hands=2) as hands:
while cap.isOpened():
# 初始化矩形
success, self.image = cap.read()
self.image = cv2.resize(self.image, (resize_w, resize_h))
if not success:
print("空帧.")
continue
# 提高性能
self.image.flags.writeable = False
# 转为RGB
self.image = cv2.cvtColor(self.image, cv2.COLOR_BGR2RGB)
# 镜像
self.image = cv2.flip(self.image, 1)
# mediapipe模型处理
results = hands.process(self.image)
self.image.flags.writeable = True
self.image = cv2.cvtColor(self.image, cv2.COLOR_RGB2BGR)
# 判断是否有手掌
if results.multi_hand_landmarks:
# 遍历每个手掌
for hand_landmarks in results.multi_hand_landmarks:
# 在画面标注手指
self.mp_drawing.draw_landmarks(
self.image,
hand_landmarks,
self.mp_hands.HAND_CONNECTIONS,
self.mp_drawing_styles.get_default_hand_landmarks_style(),
self.mp_drawing_styles.get_default_hand_connections_style())
# 解析手指,存入各个手指坐标
landmark_list = []
# 用来存储手掌范围的矩形坐标
paw_x_list = []
paw_y_list = []
for landmark_id, finger_axis in enumerate(
hand_landmarks.landmark):
landmark_list.append([
landmark_id, finger_axis.x, finger_axis.y,
finger_axis.z
])
paw_x_list.append(finger_axis.x)
paw_y_list.append(finger_axis.y)
if landmark_list:
# 比例缩放到像素
ratio_x_to_pixel = lambda x: math.ceil(x * resize_w)
ratio_y_to_pixel = lambda y: math.ceil(y * resize_h)
# 设计手掌左上角、右下角坐标
paw_left_top_x, paw_right_bottom_x = map(ratio_x_to_pixel,
[min(paw_x_list), max(paw_x_list)])
paw_left_top_y, paw_right_bottom_y = map(ratio_y_to_pixel,
[min(paw_y_list), max(paw_y_list)])
# 给手掌画框框
cv2.rectangle(self.image, (paw_left_top_x - 30, paw_left_top_y - 30),
(paw_right_bottom_x + 30, paw_right_bottom_y + 30), (0, 255, 0), 2)
# 获取中指指尖坐标
middle_finger_tip = landmark_list[12]
middle_finger_tip_x = ratio_x_to_pixel(middle_finger_tip[1])
middle_finger_tip_y = ratio_y_to_pixel(middle_finger_tip[2])
# 获取食指指尖坐标
index_finger_tip = landmark_list[8]
index_finger_tip_x = ratio_x_to_pixel(index_finger_tip[1])
index_finger_tip_y = ratio_y_to_pixel(index_finger_tip[2])
# 中间点
between_finger_tip = (middle_finger_tip_x + index_finger_tip_x) // 2, (
middle_finger_tip_y + index_finger_tip_y) // 2
# print(middle_finger_tip_x)
thumb_finger_point = (middle_finger_tip_x, middle_finger_tip_y)
index_finger_point = (index_finger_tip_x, index_finger_tip_y)
# 画指尖2点
circle_func = lambda point: cv2.circle(self.image, point, 10, (255, 0, 255), -1)
self.image = circle_func(thumb_finger_point)
self.image = circle_func(index_finger_point)
self.image = circle_func(between_finger_tip)
# 画2点连线
self.image = cv2.line(self.image, thumb_finger_point, index_finger_point, (255, 0, 255), 5)
# 勾股定理计算长度
line_len = math.hypot((index_finger_tip_x - middle_finger_tip_x),
(index_finger_tip_y - middle_finger_tip_y))
# 将指尖距离映射到文字
rect_percent_text = math.ceil(line_len)
# 激活模式,需要让矩形跟随移动
if squareManager.drag_active:
# 更新方块
squareManager.updateSquare(between_finger_tip[0], between_finger_tip[1])
if (line_len > 100):
# 取消激活
squareManager.drag_active = False
squareManager.active_index = -1
elif (line_len < 100) and (squareManager.checkOverlay(between_finger_tip[0],
between_finger_tip[1]) != -1) and (
squareManager.drag_active == False):
# 激活
squareManager.drag_active = True
# 计算距离
squareManager.setLen(between_finger_tip[0], between_finger_tip[1])
# 显示方块,传入本实例,主要为了半透明的处理
squareManager.display(self)
# 显示距离
cv2.putText(self.image, "Distance:" + str(rect_percent_text), (10, 120), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 0, 0), 3)
# 显示当前激活
cv2.putText(self.image, "Active:" + (
"None" if squareManager.active_index == -1 else str(squareManager.active_index)), (10, 170),
cv2.FONT_HERSHEY_PLAIN, 3, (255, 0, 0), 3)
# 显示刷新率FPS
cTime = time.time()
fps_text = 1 / (cTime - fpsTime)
fpsTime = cTime
cv2.putText(self.image, "FPS: " + str(int(fps_text)), (10, 70),
cv2.FONT_HERSHEY_PLAIN, 3, (255, 0, 0), 3)
# 显示画面
# self.image = cv2.resize(self.image, (resize_w//2, resize_h//2))
cv2.imshow('virtual drag and drop', self.image)
if cv2.waitKey(5) & 0xFF == 27 :
break
cap.release()
# 开始程序
control = HandControlVolume()
control.recognize()自己答案:
import cv2
import mediapipe as mp
import math
import time
video = cv2.VideoCapture(0)
#激活方块标志
sign = False
#获取视频长宽
video_width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
video_height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
#正方形相关参数
rec_width = 150
rec_height = 150
dis_x = now_posx = start_posx = 50
dis_y = now_posy = start_posy = 50
#mediapipe相关参数
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
model_complexity=0, #模型复杂度
min_detection_confidence=0.5, #检测最小置信度
min_tracking_confidence=0.5) #手部跟踪最小置信度
start_time = time.time()
def rectangle_draw(start, img, x, y):
#情况一:画黄色矩形
if start:
img = cv2.rectangle(img, (x, y), (x + rec_width, y + rec_height), (0, 255, 0), -1)
#情况二:画绿色矩形
elif start == False:
img = cv2.rectangle(img, (x, y), (x + rec_width, y + rec_height), (255, 255, 0), -1)
while True:
ret, frame = video.read()
#将cv2的BGR格式转换成RGB
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 镜像
frame = cv2.flip(frame,1)
# if sign == False:
# rec_x = dis_x
# rec_y = dis_y
# #绘制实心正方形
# frame = cv2.rectangle(frame, (rec_x, rec_y), (rec_x + rec_width, rec_y + rec_height), (0, 255, 0), -1)
results = hands.process(frame)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
#获得食指坐标x,y
finger1_x = int(hand_landmarks.landmark[8].x * video_width)
finger1_y = int(hand_landmarks.landmark[8].y * video_height)
#print(finger1_x, finger1_y)
#获得中指坐标x,y
finger2_x = int(hand_landmarks.landmark[12].x * video_width)
finger2_y = int(hand_landmarks.landmark[12].y * video_height)
#print(finger2_x, finger2_y)
#验证是否是食指、中指
# frame = cv2.circle(frame, (finger1_x, finger1_y), 30, (255, 0, 0), -1)
# frame = cv2.circle(frame, (finger2_x, finger2_y), 30, (255, 0, 0), -1)
#获得中指和食指的距离——勾股定理
# distance =math.sqrt( (finger2_x - finger1_x)**2 + (finger2_x - finger1_x)**2)
distance = math.hypot((finger1_x - finger2_x), (finger1_y - finger2_y))
#print(distance)
#情况一:触发移动条件,方块跟随手指
if distance < 45:
if (finger1_x < now_posx + rec_width) and (finger1_x > now_posx) and (finger1_y > now_posy) and (finger1_y < now_posy + rec_height):
if sign == False:
sign = True
#计算矩形左上角点与食指的相对距离
dis_x = finger1_x - now_posx
dis_y = finger1_y - now_posy
#情况二:解除/原始状态
elif distance > 240:
sign = False
#避免方块移出视频画面
if now_posx + rec_width > video_width: #右限位
sign = False
now_posx = video_width - rec_width
elif now_posx < 0: #左限位
sign = False
now_posx = 0
elif now_posy < 0: #上限位
sign = False
now_posy = 0
elif now_posy + rec_height > video_height: #下限位
sign = False
now_posy = video_height - rec_height
#移动跟随算法
if sign:
now_posx = finger1_x - dis_x
now_posy = finger1_y - dis_y
#绘制手指关键点
mp_drawing.draw_landmarks(
frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS,
mp_drawing_styles.get_default_hand_landmarks_style(),
mp_drawing_styles.get_default_hand_connections_style())
#矩形半透明处理
overlay = frame.copy()
rectangle_draw(sign, frame, now_posx, now_posy)
frame = cv2.addWeighted(overlay, 0.5, frame, 1 - 0.5, 0)
#左上角显示帧率
now_time = time.time()
fps = int(1/(now_time - start_time))
start_time = now_time
font = cv2.FONT_HERSHEY_PLAIN
frame = cv2.putText(img = frame, text = str(fps), org = (20, 50), fontFace = font, fontScale = 3, color = (0, 255, 255), thickness = 3, lineType = cv2.LINE_AA)
#恢复颜色
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
#显示视频画面,设置退出条件
cv2.imshow("Mac Camera", frame)
if cv2.waitKey(10) & 0xFF == 27:
break
#释放句柄
video.release()
cv2.destroyAllWindows()
实战项目 2:毛笔书体检测与识别
目标
使用传统形态学方法(腐蚀、膨胀)检测目标
使用传统机器学习方法(HOG+SVM)图像分类
形态学变换(morphological)
# 形态学变换:基于图像形状的一些简单操作,一般基于单通道图处理(常用灰度图);
# 一般有两个输入,一是要操作的图片,二是要变换的结构元素或核
# 两种基本的形态学变换是侵蚀和膨胀,他们的变种也有张开和闭合
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
img = cv2.imread('./test_imgs/j.png')
img.shape
>(150, 112, 3)gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray.shape
>(150, 112)plt.imshow(gray,cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7df3e490>
# 侵蚀 cv2.erode(图片,内核,迭代次数)
# 作用:去除白色噪点,将两个连起来的形状打散
# 核大小:3x3,迭代次数:1
kernel = np.ones((3,3),dtype=np.int8)
ersion1 = cv2.erode(gray.copy(),kernel,iterations=1)
plt.imshow(ersion1,cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7e1c9e50>
# 核大小:5x5,迭代次数:1(核大小越大,侵蚀越严重)
kernel = np.ones((5,5),dtype=np.int8)
ersion2 = cv2.erode(gray.copy(),kernel,iterations=1)
plt.imshow(ersion2,cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7b99e690>
# 核大小:5x5,迭代次数:2(核大小不变,迭代次数增加,侵蚀越严重)
kernel = np.ones((5,5),dtype=np.int8)
ersion3 = cv2.erode(gray.copy(),kernel,iterations=2)
plt.imshow(ersion3,cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7e293910>
fig,(ax1,ax2,ax3,ax4) = plt.subplots(1,4,figsize=(20,8),sharex=True,sharey=True)
ax1.axis('off')
ax1.imshow(gray.copy(),cmap='gray')
ax1.set_title('orginal image')
ax2.axis('off')
ax2.imshow(ersion1,cmap='gray')
ax2.set_title('3x3,1')
ax3.axis('off')
ax3.imshow(ersion2,cmap='gray')
ax3.set_title('5x5,1')
ax4.axis('off')
ax4.imshow(ersion3,cmap='gray')
ax4.set_title('5x5,2')
>Text(0.5, 1.0, '5x5,2')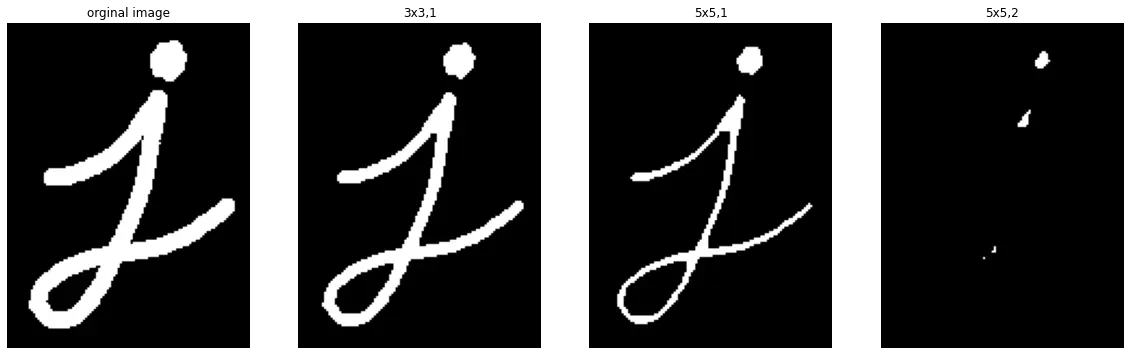
# 膨胀 cv2.dilate(图片,内核,迭代次数)
# 作用:跟在侵蚀操作后去噪点,把两个分开的部分连接起来
plt.imshow(gray.copy(),cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7eb67810>
# 核大小:3x3,迭代次数:1
kernel = np.ones((3,3),dtype=np.int8)
dilation1 = cv2.dilate(gray.copy(),kernel,iterations=1)# 核大小:5x5,迭代次数:1
kernel = np.ones((5,5),dtype=np.int8)
dilation2 = cv2.dilate(gray.copy(),kernel,iterations=1)# 核大小:5x5,迭代次数:2
kernel = np.ones((5,5),dtype=np.int8)
dilation3 = cv2.dilate(gray.copy(),kernel,iterations=2)fig,(ax1,ax2,ax3,ax4) = plt.subplots(1,4,figsize=(20,8),sharex=True,sharey=True)
ax1.axis('off')
ax1.imshow(gray.copy(),cmap='gray')
ax1.set_title('orginal image')
ax2.axis('off')
ax2.imshow(dilation1,cmap='gray')
ax2.set_title('3x3,1')
ax3.axis('off')
ax3.imshow(dilation2,cmap='gray')
ax3.set_title('5x5,1')
ax4.axis('off')
ax4.imshow(dilation3,cmap='gray')
ax4.set_title('5x5,2')
>Text(0.5, 1.0, '5x5,2')
# opening,张开 cv2.morphologyEx(图片,模型:张开,内核大小)
# 侵蚀+膨胀
# 主要用于清除噪点
img = cv2.imread('./test_imgs/cv.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
plt.imshow(gray,cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7e945550>
kernel = np.ones((10,10),dtype=np.int8)
opening1 = cv2.morphologyEx(gray.copy(),cv2.MORPH_OPEN,kernel)
kernel = np.ones((12,12),dtype=np.int8)
opening2 = cv2.morphologyEx(gray.copy(),cv2.MORPH_OPEN,kernel)
kernel = np.ones((15,15),dtype=np.int8)
opening3 = cv2.morphologyEx(gray.copy(),cv2.MORPH_OPEN,kernel)fig,(ax1,ax2,ax3,ax4) = plt.subplots(1,4,figsize=(20,8),sharex=True,sharey=True)
ax1.axis('off')
ax1.imshow(gray.copy(),cmap='gray')
ax1.set_title('orginal image')
ax2.axis('off')
ax2.imshow(opening1,cmap='gray')
ax2.set_title('10x10')
ax3.axis('off')
ax3.imshow(opening2,cmap='gray')
ax3.set_title('12x12')
ax4.axis('off')
ax4.imshow(opening3,cmap='gray')
ax4.set_title('15x15')
>Text(0.5, 1.0, '15x15')
# closing,闭合 cv2.morphologyEx(图片,模型:闭合,内核大小)
# 先膨胀再侵蚀,主要用于闭合主体内的小洞,或者一些黑色的点
plt.imshow(gray.copy(),cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7fa48890>
kernel = np.ones((20,20),dtype=np.int8)
closing1 = cv2.morphologyEx(gray.copy(),cv2.MORPH_CLOSE,kernel)
plt.imshow(closing1,cmap='gray')
><matplotlib.image.AxesImage at 0x7fad7fca9990>
Canny边缘检测算法
# canny边缘检测算法是一种流行的边缘检测方法,由John F. Canny in发明
# 算法具体的推导超出本系列课程应用,但是他主要的步骤如下
# 1.高斯模糊降噪
# 2.使用Sobel filter计算图片像素梯度
# 3.NMS非最大值抑制计算局部最大值
# 4.Hysteresis thresholding 滞后阈值法过滤
# 其中canny的两个参数T_lower、T_upper就是这里的

# 其实一般我们在使用时,要注意的就是这两个值得选择:
# A 高于阈值 maxVal 所以是真正的边界点,C 虽然低于 maxVal 但高于minVal 并且与 A 相连,所以也被认为是真正的边界点。
# 而 B 就会被抛弃,因为他不仅低于 maxVal 而且不与真正的边界点相连。
# 所以选择合适的 maxVal和 minVal 对于能否得到好的结果非常重要。
#用法:cv2.Canny(图片,minVal,maxVal)
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
img = cv2.imread('./test_imgs/pumpkin.jpg')
img_fixed = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.imshow(img_fixed)
><matplotlib.image.AxesImage at 0x7fc8de0dded0>
edges1 = cv2.Canny(img.copy(),100,200)
edges2 = cv2.Canny(img.copy(),50,200)
edges3 = cv2.Canny(img.copy(),50,100)#最大值不变,最小值越小,图片细节越多;
#最小值不变,最大值越大,图片细节越多。
fig,(ax2,ax3,ax4) = plt.subplots(1,3,figsize=(20,8),sharex=True,sharey=True)
ax2.axis('off')
ax2.imshow(edges1,cmap='gray')
ax3.axis('off')
ax3.imshow(edges2,cmap='gray')
ax4.axis('off')
ax4.imshow(edges3,cmap='gray')
><matplotlib.image.AxesImage at 0x7fc8db94fcd0>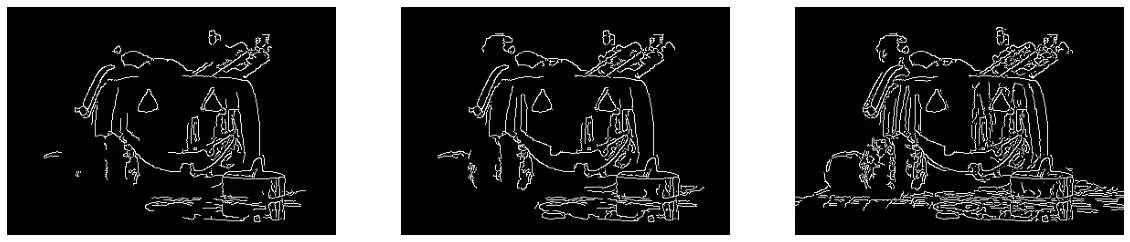
检测书法文字
# 步骤:
# 1、读取图片,灰度、二值化处理
# 2、侵蚀去噪点
# 3、膨胀连接
# 4、闭合孔洞
# 5、边缘检测
# 6、画检测框
import cv2
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib inline
plt.rcParams['figure.dpi']=200 #控制显示图片的画面大小# 读取
img = cv2.imread('./test_imgs/shufa.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)# 显示灰度图
plt.imshow(gray,cmap='gray')
><matplotlib.image.AxesImage at 0x7fe1cb59ae10>
# 二值化(理解为非此即彼)
# 用法:cv2.threshold(图片,比较值/阈值,目标值,模式)
# 作用:将画面像素与比较阈值对比,小于它则设为0(黑色),大于它则设为目标值
r,black_img = cv2.threshold(gray,100,255,cv2.THRESH_BINARY_INV)
plt.imshow(black_img,cmap='gray')
><matplotlib.image.AxesImage at 0x7fe1cc145d50>
# 边缘检测
edges = cv2.Canny(black_img,30,200)
plt.imshow(edges,cmap='gray')
><matplotlib.image.AxesImage at 0x7fe1cd6c5190>
# 找轮廓 cv2.findContours(图片,cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
coutours,h = cv2.findContours(edges,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
img_copy = img.copy()
for c in coutours:
x,y,w,h = cv2.boundingRect(c)
cv2.rectangle(img_copy,(x,y),(x+w,y+h),(0,255,0),3) #绘制矩形,用彩图,因为要画绿色
plt.imshow(img_copy)
><matplotlib.image.AxesImage at 0x7fe1cd82e190>
#可以看到,检测出来的边缘跟我们想要的整个文字的边缘的结果差距还是相当大的,因此我们就需要使用形态学变换,先将这些有笔画断开的文字变成连续的整体。
plt.imshow(black_img,cmap='gray') #使用二值化后的图片进行处理
><matplotlib.image.AxesImage at 0x7fe1cd7ba850>
# 形态学变化
# 先侵蚀,去除噪点
kernel = np.ones((3,3),dtype=np.int8)
erosion1=cv2.erode(black_img,kernel,iterations=1)
plt.imshow(erosion1,cmap='gray')
><matplotlib.image.AxesImage at 0x7fe1cd8cd6d0>
# 再膨胀
kernel = np.ones((10,10),dtype=np.int8)
dilation = cv2.dilate(erosion1,kernel,iterations=2)
plt.imshow(dilation,cmap='gray')
><matplotlib.image.AxesImage at 0x7fe1cde49690>
# 闭合
kernel = np.ones((10,10),dtype=np.int8)
closing = cv2.morphologyEx(dilation,cv2.MORPH_CLOSE,kernel)
plt.imshow(closing,cmap='gray')
><matplotlib.image.AxesImage at 0x7fe1cddd7450>
# 边缘检测
edges1 = cv2.Canny(closing,30,200)
plt.imshow(edges1,cmap='gray')
><matplotlib.image.AxesImage at 0x7fe1cc1370d0>
# 找轮廓
coutours1,h = cv2.findContours(edges1,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
img_copy = img.copy()
for c in coutours1:
x,y,w,h = cv2.boundingRect(c) #可以增加矩形大小判断,过滤太小的矩形
cv2.rectangle(img_copy,(x,y),(x+w,y+h),(0,255,0),3)
plt.imshow(img_copy)
><matplotlib.image.AxesImage at 0x7fe1d0114150>
图片分类(HOG+SVM)
HOG:方向梯度直方图
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。HOG特征通过计算和统计图像局部区域的梯度方向直方图来构成特征。
1、主要思想:
特征描述符就是通过提取图像的有用信息,并且丢弃无关信息来简化图像的表示。
HOG特征描述符可以将3通道的彩色图像转换成一定长度的特征向量。
那么我们就需要定义什么是“有用的”,什么是“无关的”。这里的“有用”,是指对于什么目的有用,显然特征向量对于观察图像是没有用的,但是它对于像图像识别和目标检测这样的任务非常有用。当将这些特征向量输入到类似支持向量机(SVM)这样的图像分类算法中时,会得到较好的结果。
那什么样的“特征”对分类任务是有用,比如我们想检测出马路上的车道线,那么我们可以通过边缘检测来找到这些车道线,在这种情况下,边缘信息就是“有用的”,而颜色信息是无关的。
在HOG特征描述符中,梯度方向的分布,也就是梯度方向的直方图被视作特征。图像的梯度(x和y导数)非常有用,因为边缘和拐角(强度突变的区域)周围的梯度幅度很大,并且边缘和拐角比平坦区域包含更多关于物体形状的信息。
方向梯度直方图(HOG)特征描述符常和线性支持向量机(SVM)配合使用,用于训练高精度的目标分类器。

梯度
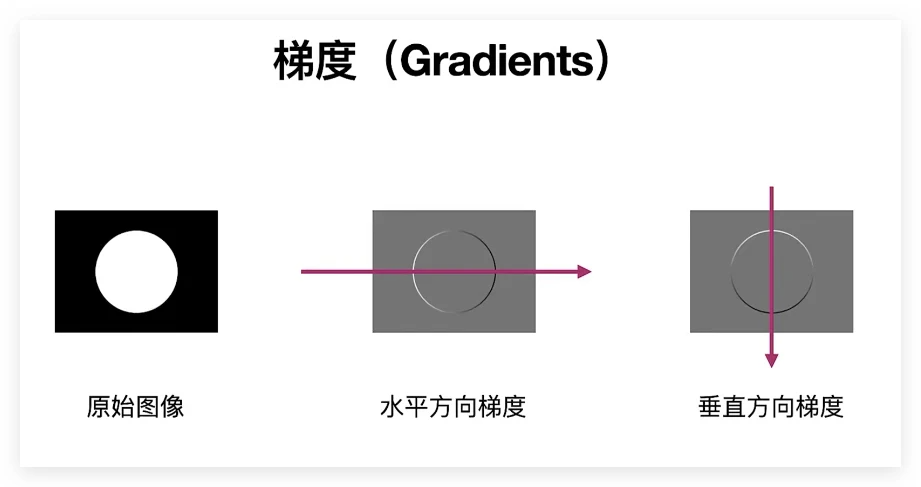
图像梯度计算的是图像变化的速度。对于图像的边缘部分,其灰度值变化较大,梯度值也较大;对于图像中比较平滑的部分,其灰度值变化较小,相应的梯度值也小。一般情况下,图像梯度计算的是图像的边缘信息。
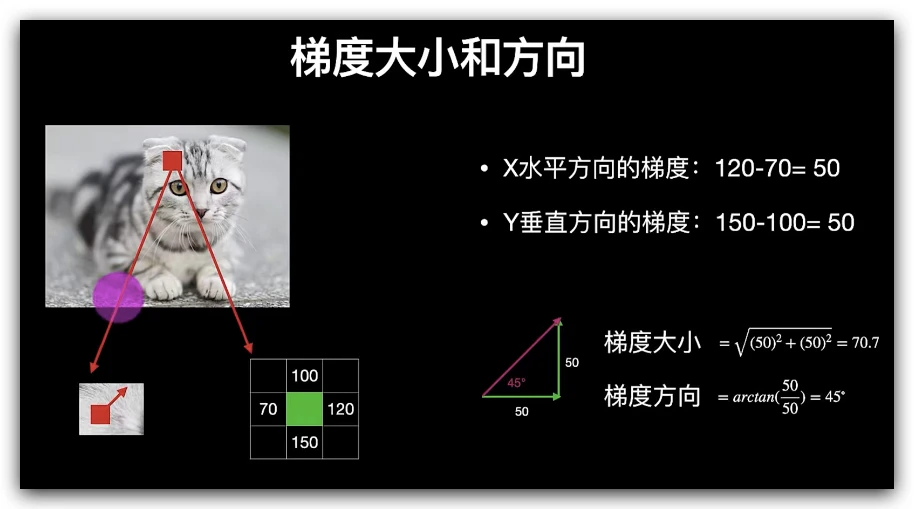
对于彩色图像,先对三通道颜色值分别计算梯度,然后取梯度值最大的那个作为该像素的梯度。
计算梯度直方图
在这一步,我们先把整个图像划分为若干个8x8的小单元,称为cell,并计算每个cell的梯度直方图。这个cell的尺寸也可以是其他值,根据具体的特征而定。
为什么我们要把图像分成若干个8x8的小单元?
这是因为对于一整张梯度图,其中的有效特征是非常稀疏的,不但运算量大,而且效果可能还不好。于是我们就使用特征描述符来表示一个更紧凑的特征。一个8x8的小单元就包含了8x8x2 = 128个值,因为每个像素包括梯度的大小和方向。
现在我们要把这个8x8的小单元用长度为9的数组来表示,这个数组就是梯度直方图。这种表示方法不仅使得特征更加紧凑,而且对单个像素值的变化不敏感,也就是能够抗噪声干扰。
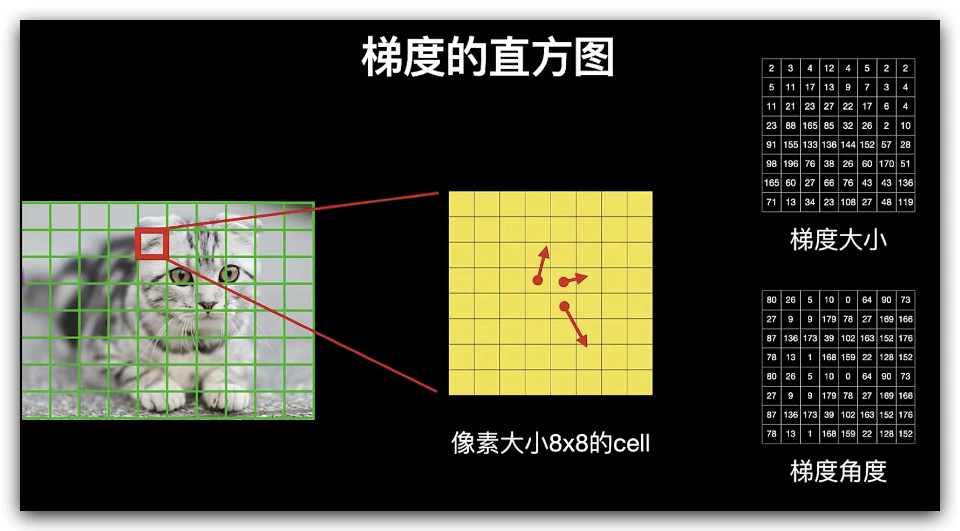
中间那张图中的箭头表示梯度,箭头方向表示梯度方向,箭头长度表示梯度大小。
右图是 8×8 的cell中表示梯度的原始数字,注意角度的范围介于0到180度之间,而不是0到360度, 这被称为“无符号”梯度,因为两个完全相反的方向被认为是相同的。
现在我们来计算cell中像素的梯度直方图,先将角度范围分成9份,也就是9 bins,每20°为一个单元,也就是这些像素可以根据角度分为9组。将每一份中所有像素对应的梯度值进行累加,可以得到9个数值。直方图就是由这9个数值组成的数组,对应于角度0、20、40、60... 160。
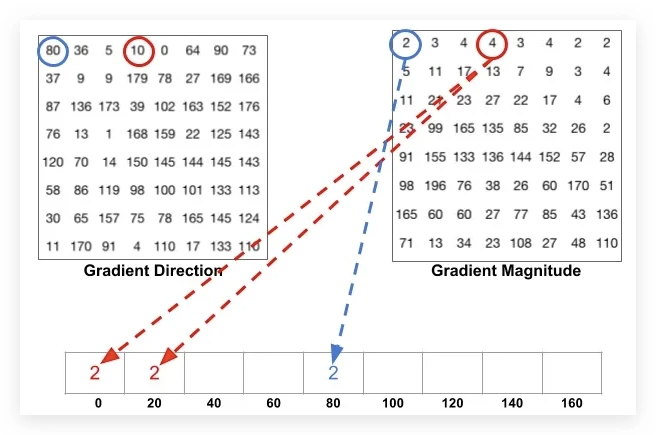
比如上面方向图中蓝圈包围的像素,角度为80度,这个像素对应的幅值为2,所以在直方图80度对应的bin加上2。红圈包围的像素,角度为10度,介于0度和20度之间,其幅值为4,那么这个梯度值就被按比例分给0度和20度对应的bin,也就是各加上2。
还有一个细节需要注意,如果某个像素的梯度角度大于160度,也就是在160度到180度之间,那么把这个像素对应的梯度值按比例分给0度和160度对应的bin。
将这 8x8 的cell中所有像素的梯度值加到各自角度对应的bin中,就形成了长度为9的直方图:
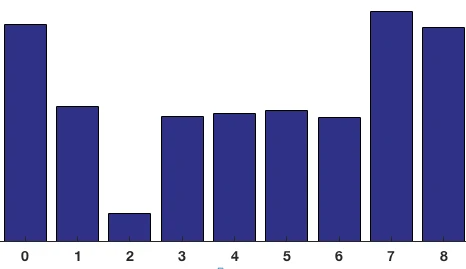
可以看到直方图中,0度和160附近有很大的权重,说明了大多数像素的梯度向上或者向下,也就是这个cell是个横向边缘。
现在我们就可以用这9个数的梯度直方图来代替原来很大的三维矩阵,即代替了8x8x2个值。
Block 归一化
HOG将8×8的一个区域作为一个cell,再以2×2个cell作为一组,称为block。由于每个cell有9个值,2×2个cell则有36个值,HOG是通过滑动窗口的方式来得到block的,如下图所示:

在前面的步骤中,我们基于图像的梯度对每个cell创建了一个直方图。
但是图像的梯度对整体光照非常敏感,比如通过将所有像素值除以2来使图像变暗,那么梯度幅值将减小一半,因此直方图中的值也将减小一半。 理想情况下,我们希望我们的特征描述符不会受到光照变化的影响,那么我们就需要将直方图“归一化” 。

在说明如何归一化直方图之前,先看看长度为3的向量是如何归一化的。
假设我们有一个向量 [128,64,32],向量的长度为\sqrt{128^{2}+64^{2}+32^{2}}=146.64,这叫做向量的L2范数。将这个向量的每个元素除以146.64就得到了归一化向量 [0.87, 0.43, 0.22]。
现在有一个新向量,是第一个向量的2倍 [128x2, 64x2, 32x2],也就是 [256, 128, 64],我们将这个向量进行归一化,你可以看到归一化后的结果与第一个向量归一化后的结果相同。所以,对向量进行归一化可以消除整体光照的影响。
知道了如何归一化,现在来对block的梯度直方图进行归一化(注意不是cell),一个block有4个直方图,将这4个直方图拼接成长度为36的向量,然后对这个向量进行归一化。
因为使用的是滑动窗口,滑动步长为8个像素,所以每滑动一次,就在这个窗口上进行归一化计算得到长度为36的向量,并重复这个过程。

代码实现
# 导入必要包
import cv2
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline# 安装skimage(用于计算HOG)
# Conda未换源:conda install -c anaconda scikit-image
# Conda换源:conda install scikit-image
# pip: pip install scikit-image
# 导入skimage
from skimage.feature import hog
from skimage import data, exposure
img = cv2.imread('./test_imgs/cat1.jpg')
img = cv2.resize(img,(500,370))
img_fixed = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)# https://scikit-image.org/docs/dev/api/skimage.feature.html?highlight=hog#skimage.feature.hog
fd, hog_image = hog(image=img_gray, orientations=9, pixels_per_cell=(8, 8),
cells_per_block=(2, 2), visualize=True)# image:输入图像
# orientations:把180度分成几份,bin的数量
# pixels_per_cell :元组形式,一个Cell内的像素大小
# cells_per_block: 元组形式,一个Block内的Cell大小
# visualize: 是否需要可视化,如果True,hog会返回numpy图像
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 10), sharex=True, sharey=True)
ax1.axis('off')
ax1.imshow(img_fixed)
ax1.set_title('Input image')
plt.show()
# Rescale histogram for better display
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
ax2.axis('off')
ax2.imshow(hog_image_rescaled, cmap=plt.cm.gray)
ax2.set_title('Histogram of Oriented Gradients')
plt.show()
# 查看一下HOG特征大小
fd.shape
>(98820,)fd
>array([0.28139531, 0. , 0.19306082, ..., 0.27718241, 0.13895444,
0.12632074])SVM(支持向量机)
如果在 n 维空间中有点,并且点上有类标签,线性支持向量机将使用平面来划分空间,使得不同的类位于平面的不同侧面。在下图中,我们用红点和蓝点表示两个类。如果将这些数据输入到线性支持向量机中,它将很容易地通过找到清楚地分隔两个类的行来构建分类器。有很多行可以分隔这些数据。SVM 选择在任一类的最大距离数据点处的那个。

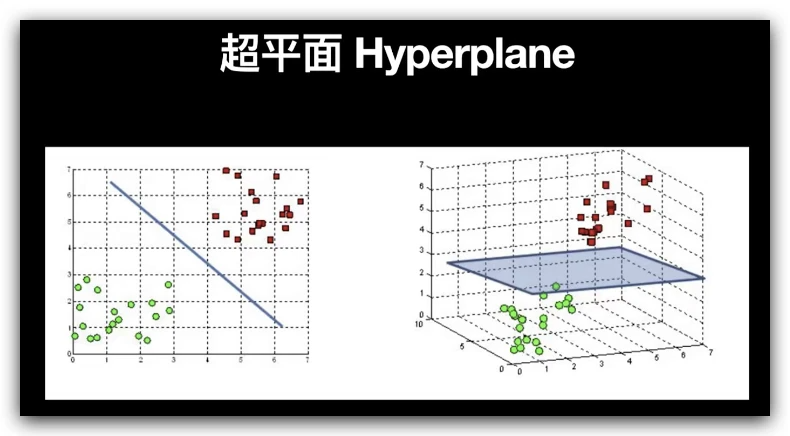
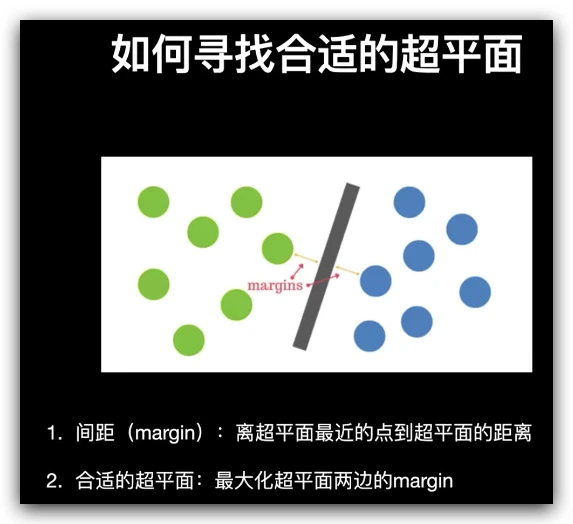
我们的图像描述符不是二维空间中的点,而是81维空间中的点,因为它们由一个81 × 1的矢量表示。附加在这些点上的类标签是图像中包含的数字,即0,1,2,... 9。支持向量机将在一个高维空间中寻找超平面来进行分类,而不是在二维空间中寻找直线。
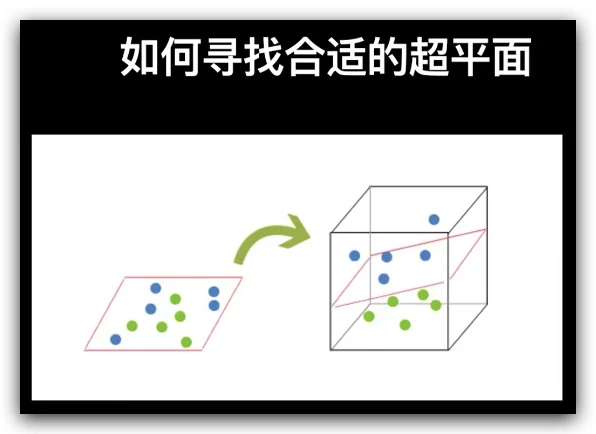
下图显示了使用不可线性分离的红点和蓝点的两个类。不能在平面上画一条线来分隔这两个类。一个好的分类器,用黑线表示,更像是一个圆。
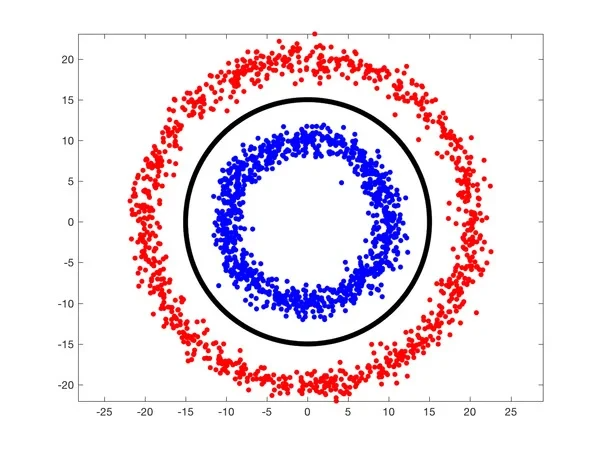
在现实生活中,数据是混乱的,不能线性分离。为了实现使用SVM进行分类,您可以使用一种称为内核技巧的技术。在我们的例子中,红点和蓝点位于一个2D 平面上。让我们使用以下方程为所有数据点添加第三维。
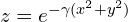
如果你曾经听到人们用“径向基核函数”这个花哨的词来形容 Gaussian Kernel,他们只不过是在谈论上面的等式。径向基函数是一个简单的实值函数,它只取决于与原点的距离(即只取决于\sqrt{x^{2}+y^{2}})。高斯核是指上述方程的高斯形式。更一般地说,RBF 可以有不同种类的内核。所以,我们根据另外两个维度的数据创造了一个第三维度。下图显示了这个三维(x,y,z)数据。我们可以看到它是可以被包含黑色圆圈的平面分开的!
参数 γ 控制第三维中的数据拉伸。它有助于分类,但它也扭曲了数据。像金发姑娘一样,你必须选择这个参数“恰到好处”。这是人们在训练支持向量机时选择的两个重要参数之一。

OVR:将每一次的一个类作为正例,其余作为反例,总共训练N个分类器。测试的时候若仅有一个分类器预测为正的类别则对应的类别标记作为最终分类结果,若有多个分类器预测为正类,则选择置信度最大的类别作为最终分类结果。
OVO:给定数据集D这里有N个类别,这种情况下就是将这些类别两两配对,从而产生N(N−1)2个二分类任务,在测试的时候把样本交给这些分类器,然后进行投票。
代码实现
#pip install scikit-learn
#conda install -c anaconda scikit-learn
#从sklearn导入SVM包
from sklearn import svm#先看二分类
#训练样本特征,有两个样本:[0, 0]和[1, 1]
X = [[0, 0], [1, 1]]#训练样本类别标签,样本[0, 0]的标签为0,样本[1, 1]的标签为1
Y = [0, 1]
clf = svm.SVC() #构造分类器#训练
clf.fit(X, Y)#测试数据样本
test = [[2, 2]]#预测
clf.predict(test)
>array([1]) #预测结果对应标签1#多分类问题
#训练样本特征
X = [[0], [1], [2], [3], [4]]#训练样本类别标签
Y = [0, 1, 2, 3, 4]#测试数据集
test = [[1]]#选择一对一策略
clf = svm.SVC(decision_function_shape='ovo')#训练
clf.fit(X, Y)#查看投票函数
dec = clf.decision_function(test)#查看筛选函数的大小,可以看到是10,是因为ovo策略会设计5*4/2=10个分类器,然后找出概率最大的
dec.shape
>(1, 10)#选择一对多策略
clf1 = svm.SVC(decision_function_shape='ovr')
clf1.fit(X, Y)#查看投票函数
dec1 = clf1.decision_function(test)#查看筛选函数的大小,可以看到是5,是因为ovr策略会设计5个分类器,然后找出概率最大的
dec1.shape
>(1, 5)代码实现
#采集图片位置:'./images/行书/丙/敬世江_5945d30c02c1e30a89de9dc3920a0011adc9aa46.jpg'
#任务:将书法图片分成五类(篆书、隶书、草书、行书、楷书)
#读取数据
#提取HOG特征
#送至SVM训练
#评估模型
#保存模型
#可视化看一下训练效果
# 导入必要包
import cv2
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inlinedef readimg(filename, mode):
# 解决中文路径问题
raw_data = np.fromfile(filename, dtype=np.uint8)
img = cv2.imdecode(raw_data, mode)
return imgtest_file_dir = './images/行书/丙/敬世江_5945d30c02c1e30a89de9dc3920a0011adc9aa46.jpg'
img = readimg(test_file_dir,-1)
plt.imshow(img)
><matplotlib.image.AxesImage at 0x23943faeb50>
#计算梯度直方图
from skimage.feature import hog
from skimage import data, exposure
def resizeGray(img,new_size):
img = cv2.resize(img,new_size)
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
return img
image = resizeGray(img,(200,200))
fd, hog_image = hog(image, orientations=4, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True)
# image:输入图像
# orientations:把180度分成几份,bin的数量
# pixels_per_cell :元组形式,一个Cell内的像素大小
# cells_per_block: 元组形式,一个Block内的Cell大小
# visualize: 是否需要可视化,如果True,hog会返回numpy图像
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4), sharex=True, sharey=True)
ax1.axis('off')
ax1.imshow(image, cmap=plt.cm.gray)
ax1.set_title('Input image')
# Rescale histogram for better display
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
ax2.axis('off')
ax2.imshow(hog_image_rescaled, cmap=plt.cm.gray)
ax2.set_title('Histogram of Oriented Gradients')
plt.show()
#批量读取文件数据
#提取HOG特征
import os
import glob
import random# 列出目录下的文件
def listdir_nohidden(path):
return glob.glob(os.path.join(path, '*')) #*表示通配符,表全部# 读取文件
def image_reader(file_name,new_size):
img = readimg(file_name,-1)
img = resizeGray(img,new_size)
return img# 从文件中读取特征和标签
def get_file_hog_label_list_from_disk(selectNum=1000):
char_styles = ['篆书','隶书','草书','行书','楷书']
# 特征列表和标签列表
fileFeaturesList = []
fileLabelList = []
# 遍历各种风格
for style in char_styles:
file_list = glob.glob('./images/'+style+'/*/*')
print('风格:{style}下共有{num}张图片\n'.format(style=style,num = len(file_list)))
# 打乱顺序
random.shuffle(file_list)
# 挑选固定数量文件
select_files = file_list[:selectNum]
# 挑选指定数量文件
for file_item in select_files:
# 读取文件
img = image_reader(file_item,(100,100))
# 提取特征
features = hog(img, orientations=4, pixels_per_cell=(6,6),cells_per_block=(2,2))
features = list(features)
fileFeaturesList.append(features)
# 提取标签,索引值对应不同的书法风格
fileLabelList.append(char_styles.index(style))
print('风格:{style},共挑选了{num}张图片\n\n'.format(style=style,num = len(select_files)))
return fileFeaturesList,fileLabelList#开始训练
from sklearn.model_selection import train_test_split #将样本分为训练和测试样本
from sklearn.neighbors import KNeighborsClassifier
from sklearn import svm #导入SVM训练器
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix #导入融合矩阵,评价模型效果# 每个字最多挑选1个
fileFeaturesList,fileLabelList = get_file_hog_label_list_from_disk(selectNum=1000)# 将样本分为训练和测试样本,一般30%设置为测试样本,剩下70%用作训练
#x_train训练样本
#x_test测试样本
#y_train训练样本标签
#y_test测试样本标签
x_train,x_test,y_train,y_test = train_test_split(fileFeaturesList,fileLabelList,
test_size=0.25,random_state=42)
>风格:篆书下共有9906张图片
风格:篆书,共挑选了1000张图片
风格:隶书下共有18337张图片
风格:隶书,共挑选了1000张图片
风格:草书下共有42917张图片
风格:草书,共挑选了1000张图片
风格:行书下共有43417张图片
风格:行书,共挑选了1000张图片
风格:楷书下共有20670张图片
风格:楷书,共挑选了1000张图片# 统计各种类别数量
from collections import Counter
Counter(fileLabelList)
>Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
len(fileLabelList)
>5000# SVM分类器
cls = svm.SVC(kernel='rbf') #默认方法
cls.fit(x_train,y_train)
predictLabels = cls.predict(x_test)
print ( "svm acc:%s" % accuracy_score(y_test,predictLabels))
cls1 = svm.SVC(kernel='linear')
cls1.fit(x_train,y_train)
predictLabels = cls1.predict(x_test)
print ( "svm 1 acc:%s" % accuracy_score(y_test,predictLabels))
cls2 = svm.SVC(kernel='poly')
cls2.fit(x_train,y_train)
predictLabels = cls2.predict(x_test)
print ( "svm 2 acc:%s" % accuracy_score(y_test,predictLabels))
>svm acc:0.7568
svm 1 acc:0.6736
svm 2 acc:0.7536# KNN
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(x_train,y_train)
predictLabels = neigh.predict(x_test)
print ("KNN acc:%s" % accuracy_score(y_test,predictLabels))
>KNN acc:0.6384# 保存模型
from joblib import dump, load
dump(cls, './models/svc.joblib')
dump(neigh, './models/neigh.joblib')
>['./models/neigh.joblib']# 调用模型
cls = load('./models/svc.joblib')
predictLabels = cls.predict(x_test)
print ( "svm acc:%s" % accuracy_score(y_test,predictLabels))
>svm acc:0.7568#查看模型效果
cm = confusion_matrix(y_test, predictLabels)
cm
>array([[237, 5, 8, 2, 14],
[ 6, 214, 4, 1, 17],
[ 8, 10, 130, 67, 21],
[ 4, 4, 60, 177, 19],
[ 7, 23, 14, 10, 188]])import seaborn as sn
import pandas as pd
df_cm = pd.DataFrame(cm, index = [i for i in ['Zhuan','Li','Cao','Xing','Kai']],
columns = [i for i in ['Zhuan','Li','Cao','Xing','Kai']])
plt.figure(figsize = (10,7))
sn.heatmap(df_cm, annot=True,cmap="Greens",fmt="d")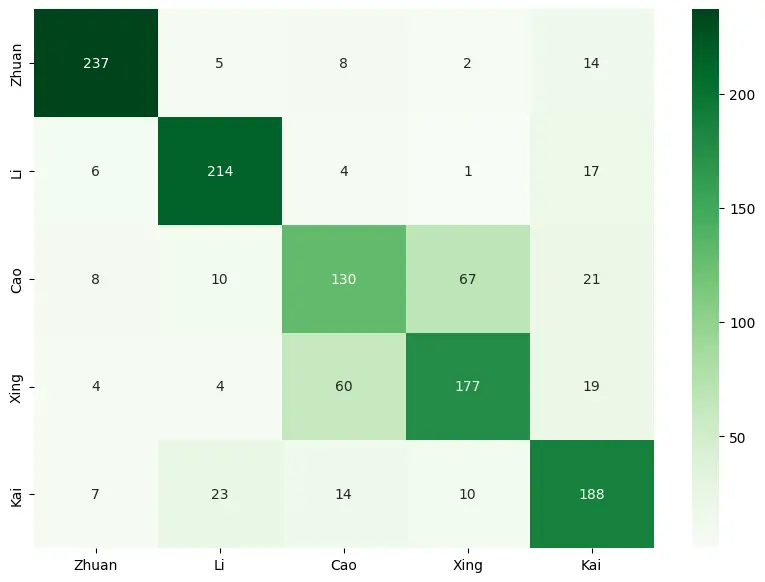
横向表示真实标签,纵向表示测试样本得到的标签。例如第一行第一列的237,表示在篆书的测试样本中,有237个被识别为了篆书。即对角线的绿色越深,其他色块颜色越浅,识别的准确率越高。
实战项目 3:人脸考勤机
人脸检测方法概述
Haar cascade + opencv
HOG + Dlib
CNN + Dlib
SSD
MTCNN
各种检测方法对比
视频中的人脸检测
Haar特征
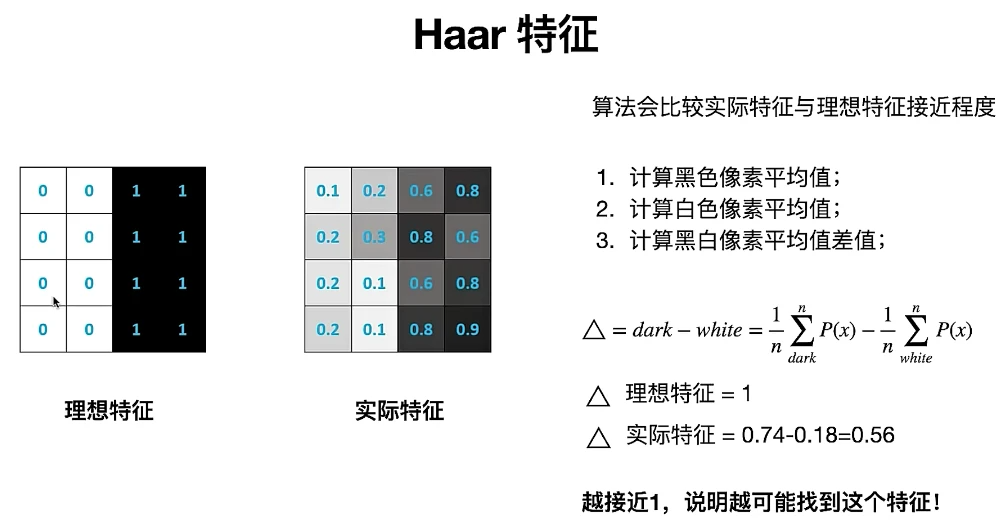
Haar特征是由Paul Viola和Michael Jones在其2001年的论文中提出的,用于快速的面部检测。Haar特征是一种在图像处理中用于对象识别的特征集,它基于图像的局部区域内像素强度的差异。
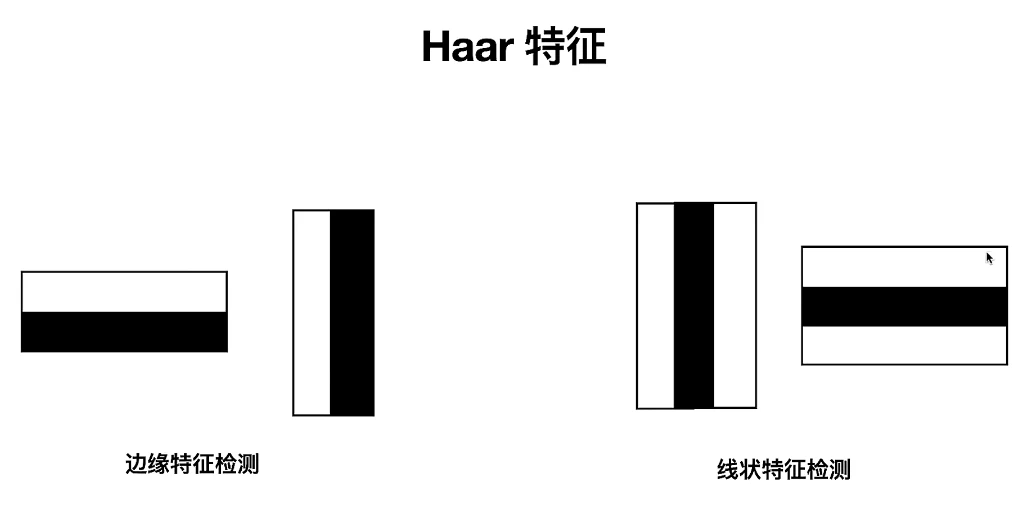
Haar特征由边缘特征、线特征、矩形特征和中心-周围特征四种基本类型组成,这些特征由连接的矩形区域组成,每个区域内像素的和计算出来,然后从相邻矩形区域的和中减去,得到的结果就是Haar特征的值。这些矩形特征通常被应用在灰度图像上。
例如,一个简单的Haar特征可能是由两个并排的矩形组成的,一个矩形覆盖图像的某个区域,另一个矩形覆盖紧邻的相同大小的区域。如果第一个矩形内的像素平均强度明显不同于第二个矩形内的像素平均强度,那么这个特征的值就会很大,表明这一区域可能包含了图像的某种边缘或者颜色变化。