机器学习
机器学习应用
通俗来讲,机器学习是指从数据中学习出有用知识的技术。以学习模式分类,机器学习可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)等。
监督学习是已知输入和输出的对应关系下的机器学习场景。比如给定输入图像和它对应的离散标签。
无监督学习是只有输入数据但不知道输出标签下的机器学习场景。比如给定一堆猫和狗的图像,自主学会猫和狗的分类,这种无监督分类也称为聚类(Clustering)。
强化学习则是给定一个学习环境和任务目标,算法自主地去不断改进自己以实现任务目标。比如 AlphaGo围棋就是用强化学习实现的,给定的环境是围棋的规则,而目标则是胜利得分。
机器学习框架
为了支持在不同应用中高效开发机器学习算法,人们设计和实现了机器学习框架(如TensorFlow、PyTorch、MindSpore等)。
机器学习框架用于训练和开发机器学习模型。
这些框架提供了一组工具和库,用于数据预处理、特征工程、模型构建、训练和评估。
机器学习框架旨在简化机器学习模型的开发过程,并提供各种算法和技术供数据科学家和机器学习工程师使用。
一些流行的机器学习框架包括Scikit-learn、TensorFlow、PyTorch、Keras等。
这些框架通常用Python等高级编程语言编写,并提供了方便的API和文档。
机器学习框架的设计目标
神经网络编程
自动微分:训练神经网络会具有模型参数。这些参数需要通过持续计算梯度(Gradients)迭代改进。梯度的计算往往需要结合训练数据、数据标注和损失函数(Loss Function)。考虑到大多数开发人员并不具备手工计算梯度的知识,机器学习框架需要根据开发人员给出的神经网络程序,全自动地计算梯度。这一过程被称之为自动微分。
数据管理和处理:机器学习的核心是数据。这些数据包括训练、验证、测试数据集和模型参数。因此,需要系统本身支持数据读取、存储和预处理(例如数据增强和数据清洗)。
模型训练和部署:为了让机器学习模型达到最佳的性能,需要使用优化方法(例如Mini-Batch SGD)来通过多步迭代反复计算梯度,这一过程称之为训练。训练完成后,需要将训练好的模型部署到推理设备。
硬件加速器:神经网络的相关计算往往通过矩阵计算实现。这一类计算可以被硬件加速器(例如,通用图形处理器-GPU)加速。因此,机器学习系统需要高效利用多种硬件加速器。
分布式执行:随着训练数据量和神经网络参数量的上升,机器学习系统的内存用量远远超过了单个机器可以提供的内存。因此,机器学习框架需要天然具备分布式执行的能力。
早年诞生的机器学习框架有着这那的不足和兼容问题,许多公司开发人员和大学研究人员开始从头设计和实现针对机器学习的软件框架。在短短数年间,机器学习框架如雨后春笋般出现(较为知名的例子包括TensorFlow、PyTorch、MindSpore、MXNet、PaddlePaddle、OneFlow、CNTK等),极大推进了人工智能在上下游产业中的发展。
机器学习框架基本构成
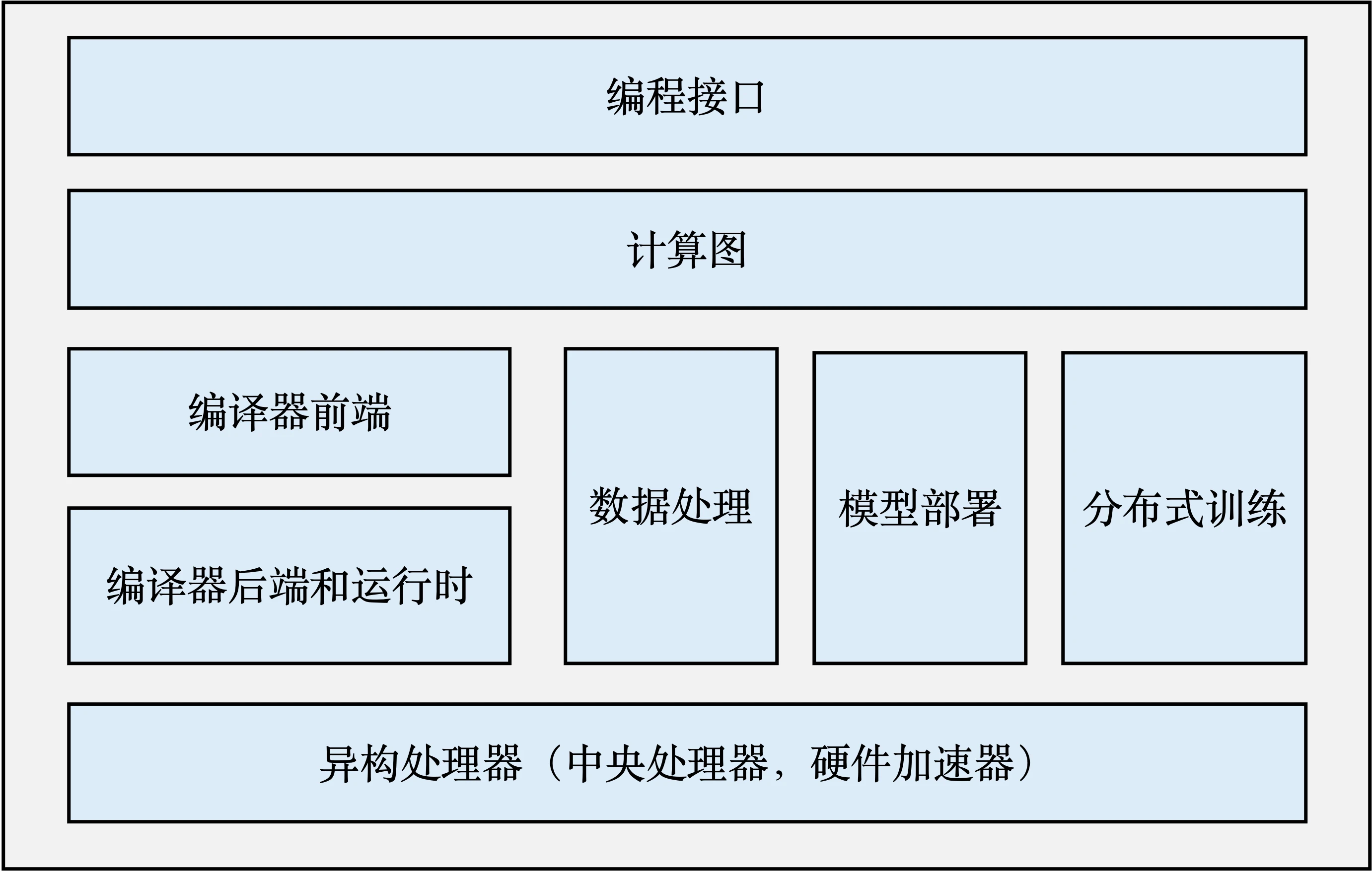
编程接口: 考虑到机器学习开发人员背景的多样性,机器学习框架首先需要提供以高层次编程语言(如Python)为主的编程接口。同时,机器学习框架为了优化运行性能,需要支持以低层次编程语言(如C和C++)为主的系统实现,从而实现操作系统(如线程管理和网络通讯等)和各类型硬件加速器的高效使用。
计算图: 利用不同编程接口实现的机器学习程序需要共享一个运行后端。实现这一后端的关键技术是计算图技术。计算图定义了用户的机器学习程序,其包含大量表达计算操作的算子节点(Operator Node),以及表达算子之间计算依赖的边(Edge)。
编译器前端: 机器学习框架往往具有AI编译器来构建计算图,并将计算图转换为硬件可以执行的程序。这个编译器首先会利用一系列编译器前端技术实现对程序的分析和优化。编译器前端的关键功能包括实现中间表示、自动微分、类型推导和静态分析等。
编译器后端和运行时: 完成计算图的分析和优化后,机器学习框架进一步利用编译器后端和运行时实现针对不同底层硬件的优化。常见的优化技术包括分析硬件的L2/L3缓存大小和指令流水线长度,优化算子的选择或者调度顺序。
异构处理器: 机器学习应用的执行由中央处理器(Central Processing Unit,CPU)和硬件加速器(如英伟达GPU、华为Ascend和谷歌TPU)共同完成。其中,非矩阵操作(如复杂的数据预处理和计算图的调度执行)由中央处理器完成。矩阵操作和部分频繁使用的机器学习算子(如Transformer算子和Convolution算子)由硬件加速器完成。
数据处理: 机器学习应用需要对原始数据进行复杂预处理,同时也需要管理大量的训练数据集、验证数据集和测试数据集。这一系列以数据为核心的操作由数据处理模块(例如TensorFlow的tf.data和PyTorch的DataLoader)完成。
模型部署: 在完成模型训练后,机器学习框架下一个需要支持的关键功能是模型部署。为了确保模型可以在内存有限的硬件上执行,会使用模型转换、量化、蒸馏等模型压缩技术。同时,也需要实现针对推理硬件平台(例如英伟达Orin)的模型算子优化。最后,为了保证模型的安全(如拒绝未经授权的用户读取),还会对模型进行混淆设计。
分布式训练: 机器学习模型的训练往往需要分布式的计算节点并行完成。其中,常见的并行训练方法包括数据并行、模型并行、混合并行和流水线并行。这些并行训练方法通常由远端程序调用(Remote Procedure Call, RPC)、集合通信(Collective Communication)或者参数服务器(Parameter Server)实现。
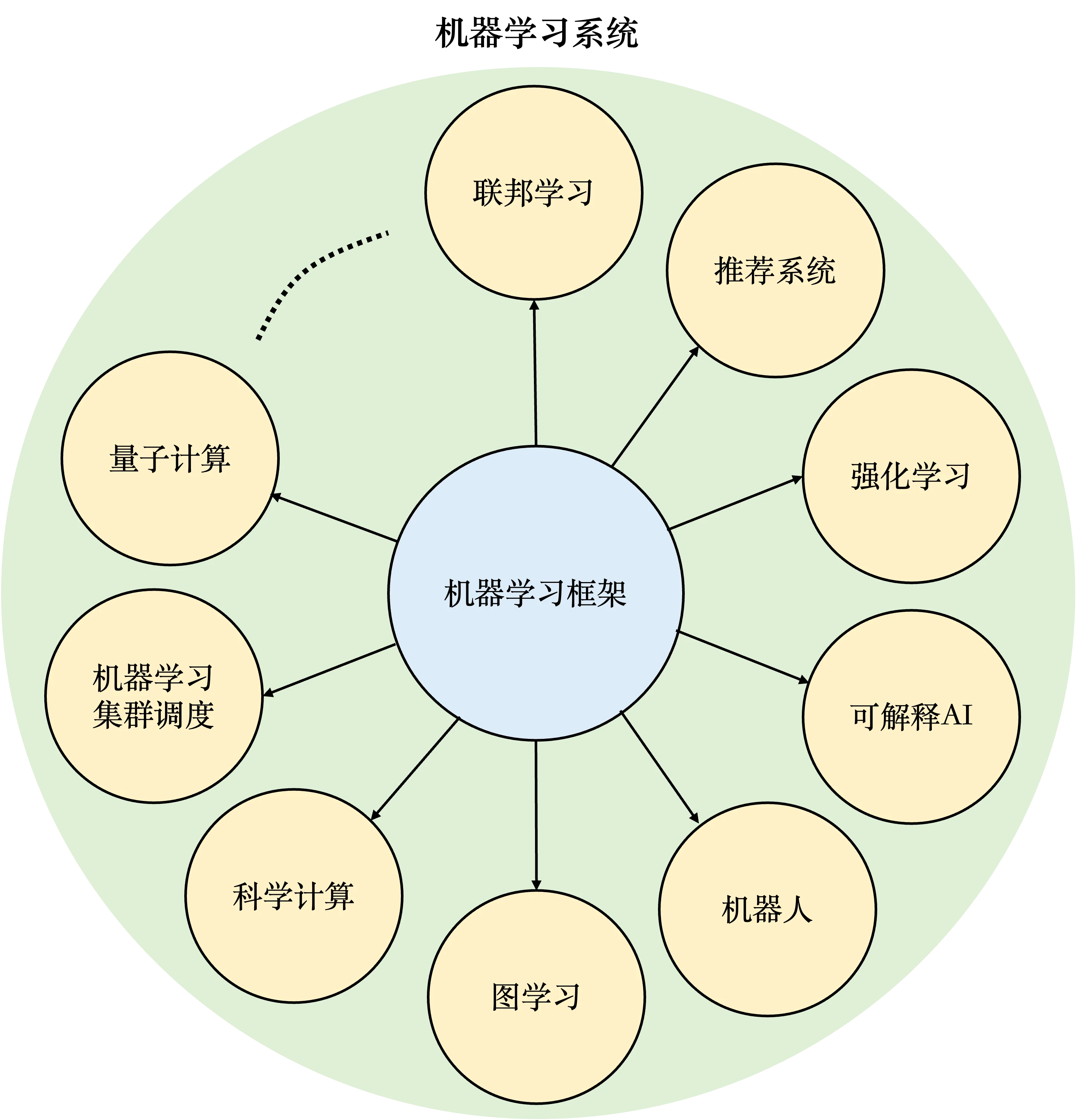
机器学习系统
机器学习系统是指实现和支持机器学习应用的各类型软硬件系统的泛称。
编程接口——如何平衡框架性能和易用性?
为了达到最优的性能,开发者需要利用硬件亲和的编程语言如:C和C++来进行开发。这是因为C和C++可以帮助机器学习框架高效地调用硬件底层API,从而最大限度发挥硬件性能。
同时,现代操作系统(如Linux和Windows)提供丰富的基于C和C++的API接口(如文件系统、网络编程、多线程管理等),通过直接调用操作系统API,可以降低框架运行的开销。
从易用性的角度分析,机器学习框架的使用者往往具有丰富的行业背景(如数据科学家、生物学家、化学家、物理学家等)。他们常用的编程语言是高层次脚本语言:Python、Matlab、R和Julia。相比于C和C++,这些语言在提供编程易用性的同时,丧失了C和C++对底层硬件和操作系统进行深度优化的能力。
机器学习框架的核心设计目标是:具有易用的编程接口来支持用户使用高层次语言,如Python实现机器学习算法;同时也要具备以C和C++为核心的低层次编程接口来帮助框架开发者用C和C++实现大量高性能组件,从而在硬件上高效执行。
机器学习编程库发展例程

(最先从科研工作者开始,少数人玩玩)这些早期的机器学习框架【Lua(Torch)和Python(Theano)】提供了机器学习必须的模型定义,自动微分等功能,其适用于编写小型和科研为导向的机器学习应用。
(硬件技术成熟,软件制约发展)2011年,深度神经网络快速崛起,需要大量的算力,旧的机器学习框架已经无法满足。计算加速卡(英伟达的GPU)的通用API接口(CUDA C)日趋成熟,用户开始希望基于C/C++来开发深度学习应用。这一类需求被Caffe等一系列以C和C++作为核心API的框架所满足。
(第一次降低使用门槛,使用C/C++)然而,机器学习模型往往需要针对部署场景、数据类型、识别任务等需求进行深度定制,而这类定制任务需要被广大的AI应用领域开发者所实现。这类开发者的背景多样,往往不能熟练使用C和C++。因此Caffe这一类与C和C++深度绑定的编程框架,成为了制约框架快速推广的巨大瓶颈。
(第二次降低使用门槛,使用Python作为操作接口,底层为C/C++)在2015年底,谷歌率先推出了TensorFlow。相比于传统的Torch,TensorFlow提出前后端分离相对独立的设计,利用高层次编程语言Python作为面向用户的主要前端语言,而利用C和C++实现高性能后端。大量基于Python的前端API确保了TensorFlow可以被大量的数据科学家和机器学习科学家接受,同时帮助TensorFlow能够快速融入Python为主导的大数据生态(大量的大数据开发库如Numpy、Pandas、SciPy、Matplotlib和PySpark)。
(开始朝着设备多样化的兼容发展)MindSpore在继承了TensorFlow、PyTorch的Python和C/C++的混合接口的基础上,进一步拓展了机器学习编程模型从而可以高效支持多种AI后端芯片(如华为Ascend、英伟达GPU和ARM芯片),实现了机器学习应用在海量异构设备上的快速部署。
机器学习工作流

机器学习系统编程模型的首要设计目标是:对开发者的整个工作流进行完整的编程支持。
环境配置
下面以MindSpore框架实现多层感知机为例,了解完整的机器学习工作流。代码运行环境为MindSpore1.5.2,Ubuntu16.04,CUDA10.1。 在构建机器学习工作流程前,MindSpore需要通过context.set_context来配置运行需要的信息,如运行模式、后端信息、硬件等信息。 以下代码导入context模块,配置运行需要的信息。
import os
import argparse
from mindspore import context
parser = argparse.ArgumentParser(description='MindSpore MLPNet Example')
parser.add_argument('--device_target', type=str, default="CPU", choices=['Ascend', 'GPU', 'CPU'])
args = parser.parse_known_args()[0]
context.set_context(mode=context.GRAPH_MODE, device_target=args.device_target)上述配置样例运行使用图模式。根据实际情况配置硬件信息,譬如代码运行在Ascend AI处理器上,则–device_target选择Ascend,代码运行在CPU、GPU同理。
数据处理
配置好运行信息后,首先讨论数据处理API的设计。MindSpore提供了用于数据处理的API模块 mindspore.dataset,用于存储样本和标签。在加载数据集前,通常会对数据集进行一些处理,mindspore.dataset也集成了常见的数据处理方法。
模型定义
完成数据的预处理后,用户需要模型定义API来定义机器学习模型。这些模型带有模型参数,可以对给定的数据进行推理。
损失函数和优化器
模型的输出需要和用户的标记进行对比,这个对比差异一般通过损失函数(Loss function)来进行评估。因此,优化器定义API允许用户定义自己的损失函数,并且根据损失来引入(Import)和定义各种优化算法(Optimisation algorithms)来计算梯度(Gradient),完成对模型参数的更新。
训练及保存模型
给定一个数据集,模型,损失函数和优化器,用户需要训练API来定义一个循环(Loop)从而将数据集中的数据按照小批量(mini-batch)的方式读取出来,反复计算梯度来更新模型。这个反复的过程称为训练。
测试和验证
测试是将测试数据集输入到模型,运行得到输出的过程。通常在训练过程中,每训练一定的数据量后就会测试一次,以验证模型的泛化能力。
泛化能力(Generalization Ability)是指机器学习模型在面对新的、未见过的数据时,能够做出正确预测或决策的能力。也就是说,模型不仅能够很好地拟合训练数据,还能够在未知数据上表现良好。
硬件加速器
1. 硬件加速器设计的意义:
- 人工智能发展的三大核心要素是数据、算法和算力,目前主要依赖CPU和GPU提供算力。
- 随着神经网络模型的复杂度和规模不断增加,CPU和GPU难以满足新型网络对算力的需求。
- 深度学习硬件加速器与传统CPU和GPU相比,具有更高的性能和更低的能耗。
- 未来智能应用的普及将广泛依赖深度学习加速器,需求量将大幅增加。
2. 硬件加速器设计的思路:
- 在体系结构研究中,能效和通用性是两个重要的衡量指标。
- 通用处理器(如CPU)通用性强但能效较低,专用集成电路(ASIC)能效高但通用性较差。
- 为提升通用处理器的能效,引入了超标量、SIMD、SIMT等加速技术。
- 业界在通用性和定制化方面有不同的硬件实现方向:
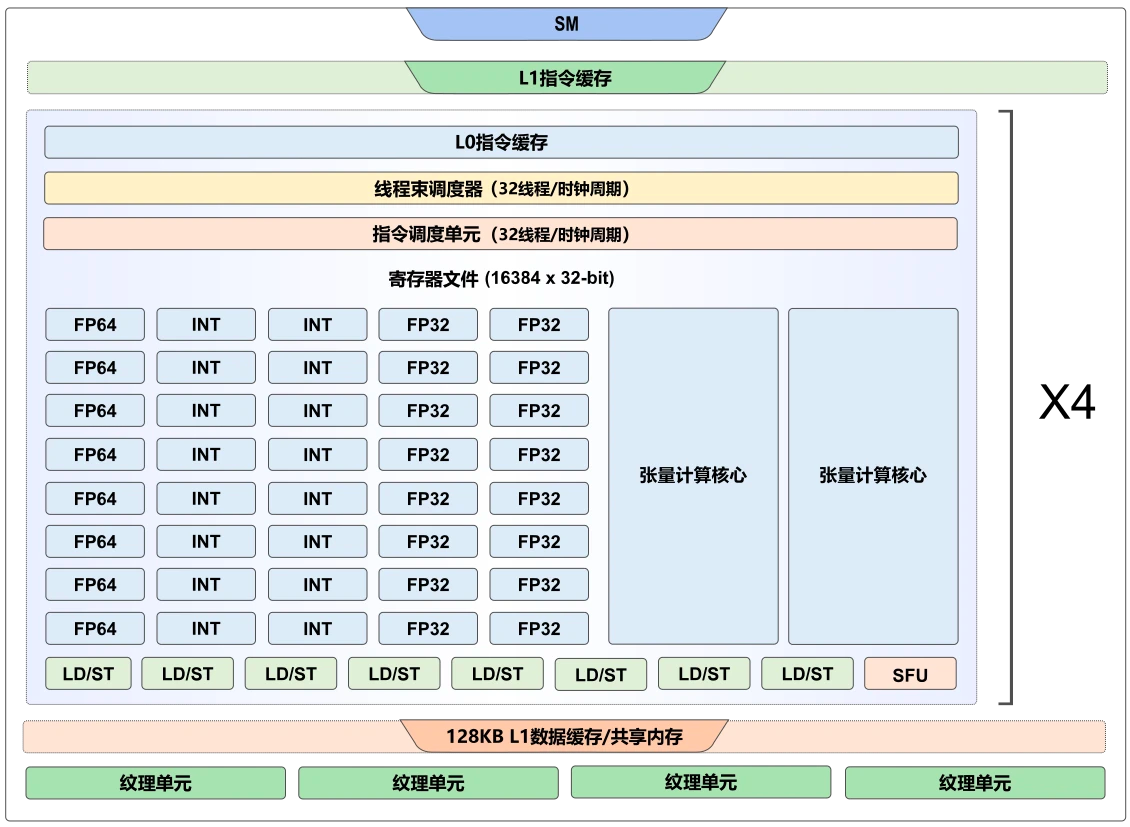
- NVIDIA在GPU上持续发力,推出Volta、Turing、Ampere等架构,引入张量计算核心(Tensor Core)加速深度学习计算。
- Google推出专门用于加速深度学习的TPU芯片,使用脉动阵列(Systolic Array)优化矩阵乘法和卷积运算。
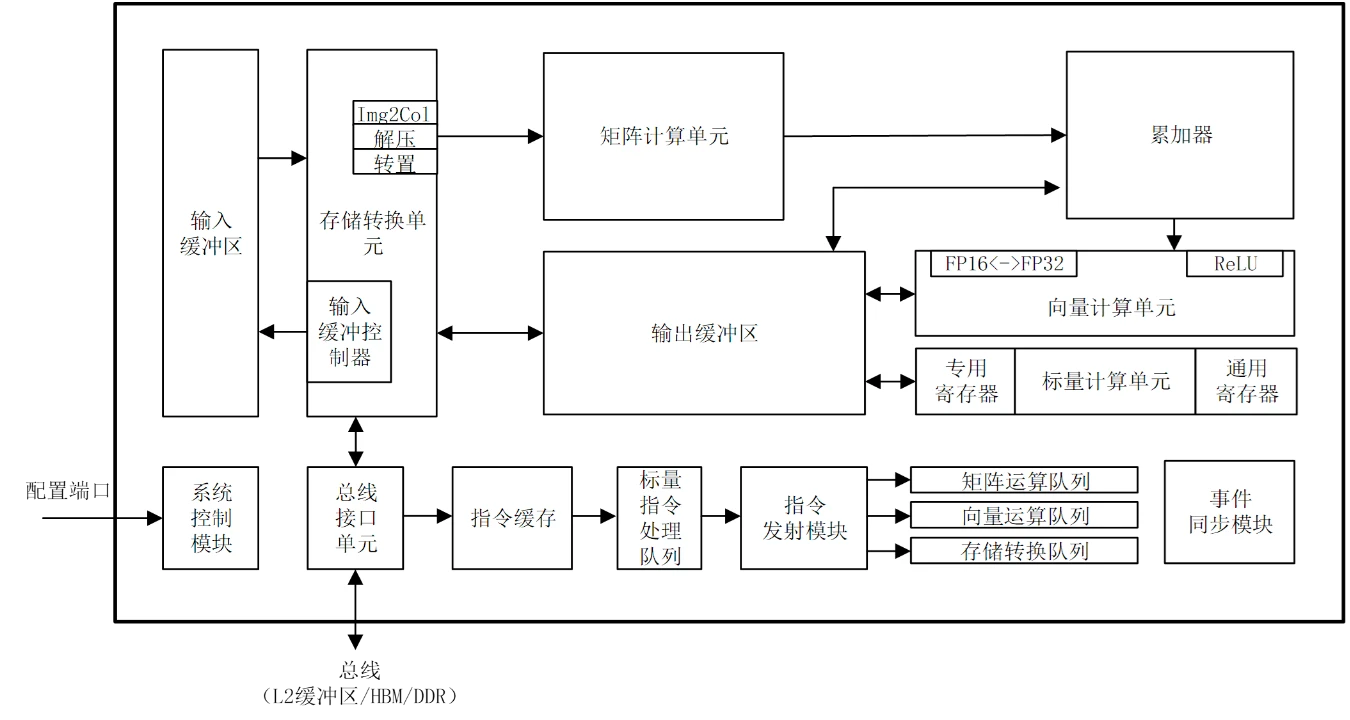
- 华为推出自研昇腾AI处理器,提供高能效算力和易用的开发部署体验,引入CUBE运算单元加速矩阵乘法。

训练模型到推理模型的转换及优化
不同的训练框架,如Tensorflow、PyTorch、MindSpore、MXNet、CNTK等,都定义了自己的模型的数据结构,推理系统需要将它们转换到统一的一种数据结构上。开发神经网络交换协议(Open Neural Network Exchange,ONNX)正是为此目的而设计的。ONNX支持广泛的机器学习运算符集合,并提供了不同训练框架的转换器,例如TensorFlow模型到ONNX模型的转换器、PyTorch模型到ONNX模型的转换器等。 模型转换本质上是将模型这种结构化的数据,从一种数据结构转换为另一种数据结构的过程。进行模型转换首先要分析两种数据结构的异同点,然后针对结构相同的数据做搬运;对于结构相似的数据做一一映射;对于结构差异较大的数据则需要根据其语义做合理的数据转换;更进一步如果两种数据结构上存在不兼容,则模型转换无法进行。ONNX的一个优势就在于其强大的表达能力,从而大多数业界框架的模型都能够转换到ONNX的模型上来而不存在不兼容的情况。